## install jika belum ada
install.packages("ranger")
install.packages("xgboost")Class Weight untuk Penanganan Class Imbalanced dengan tidymodels
R Programming
Statistical Machine Learning
tidymodels
Package
library(lares)
library(discrim)
library(tidyverse)
library(tidymodels)
library(themis)
library(tidyposterior)
library(SmartEDA)
library(DataExplorer)
library(skimr)
library(ggpubr)
library(workflowsets)Deskripsi singkat data
Tutorial kali ini akan menggunakan data yaitu German df. Berikut adalah informasi singkat mengenai data
This dataset classifies people described by a set of attributes as good or bad df risks.
Author: Dr. Hans Hofmann Source: UCI - 1994 Please cite: Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Attribute description
- Status of existing checking account, in Deutsche Mark.
- df history (dfs taken, paid back duly, delays, critical accounts)
- Purpose of the df (car, television,…)
- df amount
- Status of savings account/bonds, in Deutsche Mark.
- Present employment, in number of years.
- Installment rate in percentage of disposable income
- Personal status (married, single,…) and sex
- Other debtors / guarantors
- Present residence since X years
- Property (e.g. real estate)
- Age in years
- Other installment plans (banks, stores)
- Housing (rent, own,…)
- Number of existing dfs at this bank
- Job
- Number of people being liable to provide maintenance for
- Telephone (yes,no)
- Foreign worker (yes,no)
- Duration in months
data ini bisa diperoleh di link berikut ini
Import data di R
df <- read_csv("german_credit.csv") %>%
# convert all character column to factor
mutate(across(where(is.character),as.factor))Rows: 1000 Columns: 21
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (14): checking_status, credit_history, purpose, savings_status, employme...
dbl (7): duration, credit_amount, installment_commitment, residence_since, ...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(df)Rows: 1,000
Columns: 21
$ checking_status <fct> '<0', '0<=X<200', 'no checking', '<0', '<0', 'n…
$ duration <dbl> 6, 48, 12, 42, 24, 36, 24, 36, 12, 30, 12, 48, …
$ credit_history <fct> 'critical/other existing credit', 'existing pai…
$ purpose <fct> radio/tv, radio/tv, education, furniture/equipm…
$ credit_amount <dbl> 1169, 5951, 2096, 7882, 4870, 9055, 2835, 6948,…
$ savings_status <fct> 'no known savings', '<100', '<100', '<100', '<1…
$ employment <fct> '>=7', '1<=X<4', '4<=X<7', '4<=X<7', '1<=X<4', …
$ installment_commitment <dbl> 4, 2, 2, 2, 3, 2, 3, 2, 2, 4, 3, 3, 1, 4, 2, 4,…
$ personal_status <fct> 'male single', 'female div/dep/mar', 'male sing…
$ other_parties <fct> none, none, none, guarantor, none, none, none, …
$ residence_since <dbl> 4, 2, 3, 4, 4, 4, 4, 2, 4, 2, 1, 4, 1, 4, 4, 2,…
$ property_magnitude <fct> 'real estate', 'real estate', 'real estate', 'l…
$ age <dbl> 67, 22, 49, 45, 53, 35, 53, 35, 61, 28, 25, 24,…
$ other_payment_plans <fct> none, none, none, none, none, none, none, none,…
$ housing <fct> own, own, own, 'for free', 'for free', 'for fre…
$ existing_credits <dbl> 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1,…
$ job <fct> skilled, skilled, 'unskilled resident', skilled…
$ num_dependents <dbl> 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ own_telephone <fct> yes, none, none, none, none, yes, none, yes, no…
$ foreign_worker <fct> yes, yes, yes, yes, yes, yes, yes, yes, yes, ye…
$ class <fct> good, bad, good, good, bad, good, good, good, g…Eksplorasi Data
df %>%
count(class) %>%
rename(cat=class) %>%
mutate(label=str_c(cat,"(",n,"/",
round(n*100/sum(n),2),"%)")
) %>%
ggdonutchart(x="n",label = "label",
fill = c("#962E10","#107896"),
lab.pos = "out",
lab.font = c(5,"bold","black")
)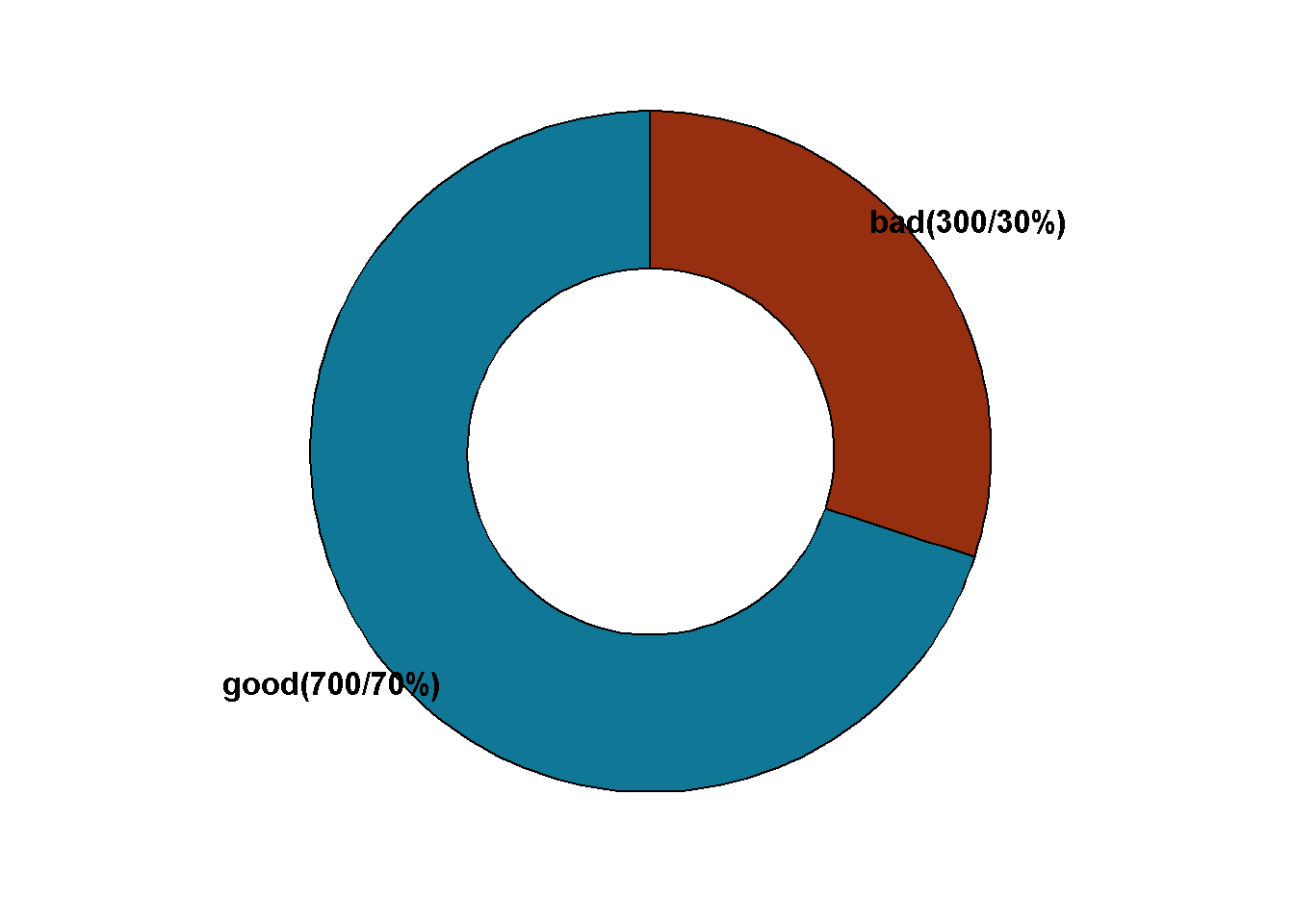
Class Weight
Class Weight adalah metode memberikan kelas/kategori minoritas (kelas yang amatanya sangat sedikit) dengan bobot yang besar sehingga model lebih memperhatikan kelas minoritas tersebut.
Misalnya pada data kelas minoritas adalah BAD, maka kita akan memberikan bobot lebih pada amatan-amatan yang masuk dalam kelas BAD tersebut. Cara menghitung bobotnya bisa menggunaan formulas berikut ini:
\[ \begin{aligned} \text{weight}_{\text{minor}} &= \frac{\text{number of observation in majority class}}{\text{number of observation in minority class}} \\ \text{weight}_{\text{major}} &= \frac{\text{number of observation in majority class}}{\text{number of observation in majority class}} =1 \end{aligned} \] Berikut adalah sintaks perhitunganya
weights <- df %>% count(class) %>%
mutate(weight=max(n)/n)
weightsBerikut syntax untuk mengekstrak bobotnya
extract_weight <- weights %>% pull(weight) %>% max()
extract_weight[1] 2.333333Kemudian, bobot tersebut kita berikan kepada amatan-amatan sesuai dengan kelasnya masing-masing. Berikut sintaksnya
df <- df %>%
mutate(
#memberikan bobot pada amatan
class_weights = if_else(class == "bad",
extract_weight, 1),
#konversi kelas object
class_weights = importance_weights(class_weights)
)Berikut ilustrasi pemberian bobot di 10 amatan pertama
df %>%
select(class,class_weights) %>%
slice_head(n = 10)Menyiapkan Pembagian Data
K-fold Cross Validation
set.seed(345)
folds <- vfold_cv(df, v = 10,strata = "class")Mendefinisikan praproses data
Pendefinisikan praproses data dapat dilakukan dengan fungsi recipe. Pada proses pendefinisian ini bobot yang sudah kita tentukan diawal sudah dikenali oleh `recipe``
class_weights_recipe <- recipe(class~.,data =df)
class_weights_recipe ── Recipe ──────────────────────────────────────────────────────────────────────── Inputs Number of variables by roleoutcome: 1
predictor: 20
case_weights: 1Karena model yang seperti linear discriminant dan XGBOOST memerlukan transformasi variabel kategorik ke numerik dengan dummy encoding maka kita membuat 1 recipe tambahan
class_weights_dummy_recipe <- recipe(class~.,data =df) %>%
step_dummy(all_nominal_predictors(),
one_hot = FALSE)
class_weights_dummy_recipe ── Recipe ──────────────────────────────────────────────────────────────────────── Inputs Number of variables by roleoutcome: 1
predictor: 20
case_weights: 1── Operations • Dummy variables from: all_nominal_predictors()class_weights_dummy_recipe %>%
prep() %>%
bake(new_data = NULL) %>%
glimpse()Rows: 1,000
Columns: 50
$ duration <dbl> 6, 48, 12, 42, 24, 36…
$ credit_amount <dbl> 1169, 5951, 2096, 788…
$ installment_commitment <dbl> 4, 2, 2, 2, 3, 2, 3, …
$ residence_since <dbl> 4, 2, 3, 4, 4, 4, 4, …
$ age <dbl> 67, 22, 49, 45, 53, 3…
$ existing_credits <dbl> 2, 1, 1, 1, 2, 1, 1, …
$ num_dependents <dbl> 1, 1, 2, 2, 2, 2, 1, …
$ class_weights <imp_wts> 1.000000, 2.33333…
$ class <fct> good, bad, good, good…
$ checking_status_X...200. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ checking_status_X.0..X.200. <dbl> 0, 1, 0, 0, 0, 0, 0, …
$ checking_status_X.no.checking. <dbl> 0, 0, 1, 0, 0, 1, 1, …
$ credit_history_X.critical.other.existing.credit. <dbl> 1, 0, 1, 0, 0, 0, 0, …
$ credit_history_X.delayed.previously. <dbl> 0, 0, 0, 0, 1, 0, 0, …
$ credit_history_X.existing.paid. <dbl> 0, 1, 0, 1, 0, 1, 1, …
$ credit_history_X.no.credits.all.paid. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ purpose_X.new.car. <dbl> 0, 0, 0, 0, 1, 0, 0, …
$ purpose_X.used.car. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ purpose_business <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ purpose_education <dbl> 0, 0, 1, 0, 0, 1, 0, …
$ purpose_furniture.equipment <dbl> 0, 0, 0, 1, 0, 0, 1, …
$ purpose_other <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ purpose_radio.tv <dbl> 1, 1, 0, 0, 0, 0, 0, …
$ purpose_repairs <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ purpose_retraining <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ savings_status_X...1000. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ savings_status_X.100..X.500. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ savings_status_X.500..X.1000. <dbl> 0, 0, 0, 0, 0, 0, 1, …
$ savings_status_X.no.known.savings. <dbl> 1, 0, 0, 0, 0, 1, 0, …
$ employment_X...7. <dbl> 1, 0, 0, 0, 0, 0, 1, …
$ employment_X.1..X.4. <dbl> 0, 1, 0, 0, 1, 1, 0, …
$ employment_X.4..X.7. <dbl> 0, 0, 1, 1, 0, 0, 0, …
$ employment_unemployed <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ personal_status_X.male.div.sep. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ personal_status_X.male.mar.wid. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ personal_status_X.male.single. <dbl> 1, 0, 1, 1, 1, 1, 1, …
$ other_parties_guarantor <dbl> 0, 0, 0, 1, 0, 0, 0, …
$ other_parties_none <dbl> 1, 1, 1, 0, 1, 1, 1, …
$ property_magnitude_X.no.known.property. <dbl> 0, 0, 0, 0, 1, 1, 0, …
$ property_magnitude_X.real.estate. <dbl> 1, 1, 1, 0, 0, 0, 0, …
$ property_magnitude_car <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ other_payment_plans_none <dbl> 1, 1, 1, 1, 1, 1, 1, …
$ other_payment_plans_stores <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ housing_own <dbl> 1, 1, 1, 0, 0, 0, 1, …
$ housing_rent <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ job_X.unemp.unskilled.non.res. <dbl> 0, 0, 0, 0, 0, 0, 0, …
$ job_X.unskilled.resident. <dbl> 0, 0, 1, 0, 0, 1, 0, …
$ job_skilled <dbl> 1, 1, 0, 1, 1, 0, 1, …
$ own_telephone_yes <dbl> 1, 0, 0, 0, 0, 1, 0, …
$ foreign_worker_yes <dbl> 1, 1, 1, 1, 1, 1, 1, …Mendefinisikan Model
KNN (K-Nearest Neighbor)
knn <- nearest_neighbor(neighbors=7,
weight_func="rectangular") %>%
set_engine("kknn") %>%
set_mode("classification")Regresi Logistik
logistic <-logistic_reg() %>%
set_engine("glm") %>%
set_mode("classification")Linear Discriminant
disc_linear <- discrim_linear()%>%
set_engine(engine = "MASS") %>%
set_mode("classification")Random Forest
rf <- rand_forest() %>%
set_engine("ranger") %>%
set_mode("classification")XGBOOST
xgb <- boost_tree() %>%
set_engine("xgboost") %>%
set_mode("classification")Komparasi dan Evaluasi Model
Menkombinasikan metode class imbalanced dan model
models <- list(knn=knn,
logistic=logistic,
rf=rf,
disc_linear=disc_linear,
xgb=xgb
)
preproc <- list(class_weights=class_weights_recipe,
class_weights=class_weights_recipe,
class_weights=class_weights_recipe,
class_weights_dummy=class_weights_dummy_recipe,
class_weights_dummy=class_weights_dummy_recipe
)
wf_set <- workflow_set(preproc = preproc,models = models,
cross = FALSE,
case_weights = class_weights)Warning: Case weights are not enabled by the underlying model implementation for the following engine(s): kknn, MASS.
The `case_weights` argument will be ignored for specifications using that engine.Training models
models_eval <- workflow_map(wf_set,
fn="fit_resamples",
resamples = folds,
control=control_resamples(save_workflow = TRUE),
metrics=metric_set(sensitivity,
specificity,
bal_accuracy,
f_meas),
seed = 2123)Evaluasi model
autoplot(models_eval,type="wflow_id",
rank_metric = "bal_accuracy")+
scale_y_continuous(limits = c(0,1)) +
theme_lares() +
# memindahkan legend ke bawah
theme(legend.position = "bottom")+
# legend menjadi 2 baris
guides(color = guide_legend(nrow = 2))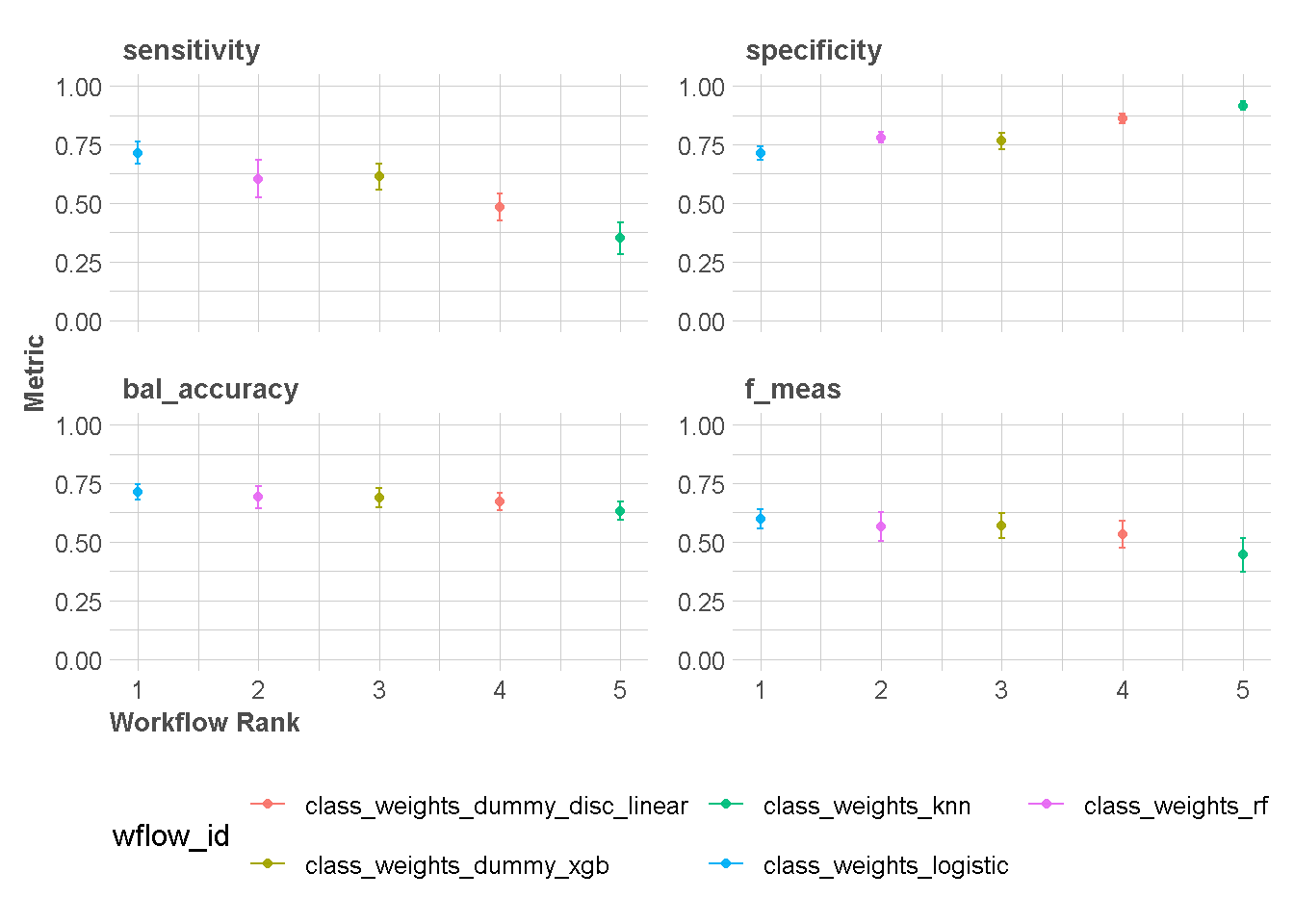
karena saat training model package MASS dipanggil otomatis maka fungsi select di dplyr tidak bisa digunakan, sehingga kita perlu menjalankan sintaks dibawah ini
select <- dplyr::selectrank_results(models_eval,rank_metric = "bal_accuracy") %>%
filter(.metric=="bal_accuracy") %>%
select(wflow_id,.metric,mean,std_err,rank)rank_results(models_eval,rank_metric = "f_meas") %>%
filter(.metric=="f_meas") %>%
select(wflow_id,.metric,mean,std_err,rank)Menentukan Model terbaik dari Training
mod_best1 <- fit_best(x = models_eval,metric = "bal_accuracy")
mod_best1══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: logistic_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
0 Recipe Steps
── Case Weights ────────────────────────────────────────────────────────────────
class_weights
── Model ───────────────────────────────────────────────────────────────────────
Call: stats::glm(formula = ..y ~ ., family = stats::binomial, data = data,
weights = weights)
Coefficients:
(Intercept)
-0.2330247
checking_status'>=200'
0.8542541
checking_status'0<=X<200'
0.4064425
checking_status'no checking'
1.7803921
duration
-0.0254334
credit_history'critical/other existing credit'
1.6034609
credit_history'delayed previously'
0.9778165
credit_history'existing paid'
0.7572802
credit_history'no credits/all paid'
0.1464931
purpose'new car'
-0.5274284
purpose'used car'
1.2482589
purposebusiness
0.1078705
purposeeducation
-0.6654258
purposefurniture/equipment
0.2111165
purposeother
1.0584504
purposeradio/tv
0.3566661
purposerepairs
-0.4869277
purposeretraining
1.4744361
credit_amount
-0.0001410
savings_status'>=1000'
1.2472587
savings_status'100<=X<500'
0.3974365
savings_status'500<=X<1000'
0.2401396
savings_status'no known savings'
...
and 57 more lines.mod_best2 <- fit_best(x = models_eval,metric = "f_meas")
mod_best2══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: logistic_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
0 Recipe Steps
── Case Weights ────────────────────────────────────────────────────────────────
class_weights
── Model ───────────────────────────────────────────────────────────────────────
Call: stats::glm(formula = ..y ~ ., family = stats::binomial, data = data,
weights = weights)
Coefficients:
(Intercept)
-0.2330247
checking_status'>=200'
0.8542541
checking_status'0<=X<200'
0.4064425
checking_status'no checking'
1.7803921
duration
-0.0254334
credit_history'critical/other existing credit'
1.6034609
credit_history'delayed previously'
0.9778165
credit_history'existing paid'
0.7572802
credit_history'no credits/all paid'
0.1464931
purpose'new car'
-0.5274284
purpose'used car'
1.2482589
purposebusiness
0.1078705
purposeeducation
-0.6654258
purposefurniture/equipment
0.2111165
purposeother
1.0584504
purposeradio/tv
0.3566661
purposerepairs
-0.4869277
purposeretraining
1.4744361
credit_amount
-0.0001410
savings_status'>=1000'
1.2472587
savings_status'100<=X<500'
0.3974365
savings_status'500<=X<1000'
0.2401396
savings_status'no known savings'
...
and 57 more lines.Prediksi Data baru
Berikut kita generate data baru dummy
set.seed(1234)
data_baru <- df %>%
slice_sample(n = 2,by = class) %>%
select(-class)
data_barupred_data_baru2 <- mod_best1 %>%
predict(new_data = data_baru)
pred_data_baru3 <- mod_best2 %>%
predict(new_data = data_baru)pred_data_baru2pred_data_baru3