library(lares)
library(tidyverse)
library(tidymodels)
library(themis)
library(tidyposterior)
library(SmartEDA)
library(DataExplorer)
library(skimr)
library(ggpubr)
library(workflowsets)KNN dengan tidymodels
R Programming
Statistical Machine Learning
tidymodels
Deskripsi singkat data
Tutorial kali ini akan menggunakan data yaitu German Credit. Berikut adalah informasi singkat mengenai data
This dataset classifies people described by a set of attributes as good or bad credit risks.
Author: Dr. Hans Hofmann Source: UCI - 1994 Please cite: Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Attribute description
- Status of existing checking account, in Deutsche Mark.
- Credit history (credits taken, paid back duly, delays, critical accounts)
- Purpose of the credit (car, television,…)
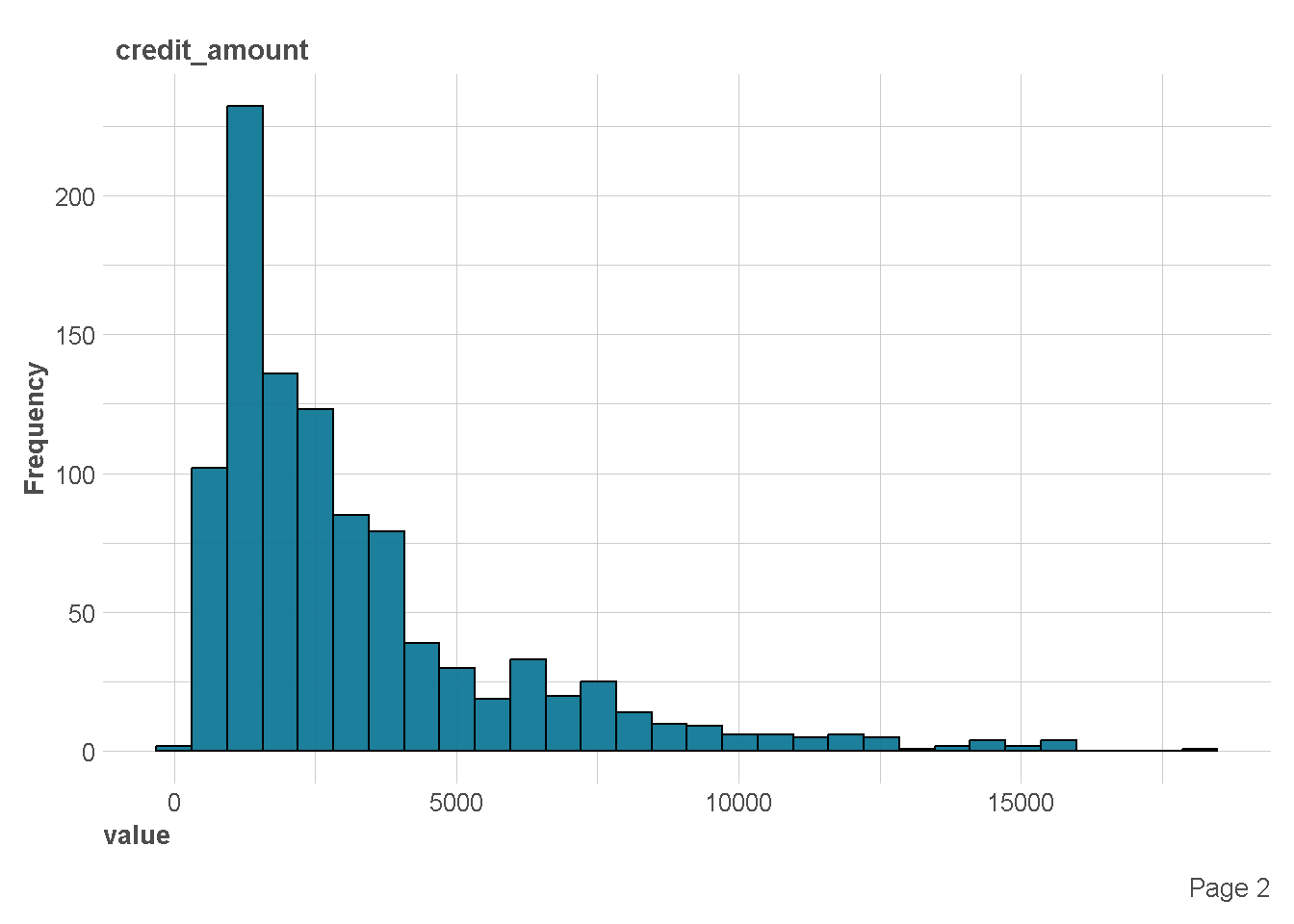
- Credit amount
- Status of savings account/bonds, in Deutsche Mark.
- Present employment, in number of years.
- Installment rate in percentage of disposable income
- Personal status (married, single,…) and sex
- Other debtors / guarantors
- Present residence since X years
- Property (e.g. real estate)
- Age in years
- Other installment plans (banks, stores)
- Housing (rent, own,…)
- Number of existing credits at this bank
- Job
- Number of people being liable to provide maintenance for
- Telephone (yes,no)
- Foreign worker (yes,no)
- Duration in months
data ini bisa diperoleh di link berikut ini
Import data di R
df <- read_csv("german_credit.csv") %>%
# convert all character column to factor
mutate(across(where(is.character),as.factor))Rows: 1000 Columns: 21
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (14): checking_status, credit_history, purpose, savings_status, employme...
dbl (7): duration, credit_amount, installment_commitment, residence_since, ...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(df)Rows: 1,000
Columns: 21
$ checking_status <fct> '<0', '0<=X<200', 'no checking', '<0', '<0', 'n…
$ duration <dbl> 6, 48, 12, 42, 24, 36, 24, 36, 12, 30, 12, 48, …
$ credit_history <fct> 'critical/other existing credit', 'existing pai…
$ purpose <fct> radio/tv, radio/tv, education, furniture/equipm…
$ credit_amount <dbl> 1169, 5951, 2096, 7882, 4870, 9055, 2835, 6948,…
$ savings_status <fct> 'no known savings', '<100', '<100', '<100', '<1…
$ employment <fct> '>=7', '1<=X<4', '4<=X<7', '4<=X<7', '1<=X<4', …
$ installment_commitment <dbl> 4, 2, 2, 2, 3, 2, 3, 2, 2, 4, 3, 3, 1, 4, 2, 4,…
$ personal_status <fct> 'male single', 'female div/dep/mar', 'male sing…
$ other_parties <fct> none, none, none, guarantor, none, none, none, …
$ residence_since <dbl> 4, 2, 3, 4, 4, 4, 4, 2, 4, 2, 1, 4, 1, 4, 4, 2,…
$ property_magnitude <fct> 'real estate', 'real estate', 'real estate', 'l…
$ age <dbl> 67, 22, 49, 45, 53, 35, 53, 35, 61, 28, 25, 24,…
$ other_payment_plans <fct> none, none, none, none, none, none, none, none,…
$ housing <fct> own, own, own, 'for free', 'for free', 'for fre…
$ existing_credits <dbl> 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1,…
$ job <fct> skilled, skilled, 'unskilled resident', skilled…
$ num_dependents <dbl> 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ own_telephone <fct> yes, none, none, none, none, yes, none, yes, no…
$ foreign_worker <fct> yes, yes, yes, yes, yes, yes, yes, yes, yes, ye…
$ class <fct> good, bad, good, good, bad, good, good, good, g…Eksplorasi Data
df %>%
skim_without_charts()| Name | Piped data |
| Number of rows | 1000 |
| Number of columns | 21 |
| _______________________ | |
| Column type frequency: | |
| factor | 14 |
| numeric | 7 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| checking_status | 0 | 1 | FALSE | 4 | ‘no: 394,’<0: 274, ‘0<: 269,’>=: 63 |
| credit_history | 0 | 1 | FALSE | 5 | ’ex: 530, ’cr: 293, ’de: 88, ’al: 49 |
| purpose | 0 | 1 | FALSE | 10 | rad: 280, ’ne: 234, fur: 181, ’us: 103 |
| savings_status | 0 | 1 | FALSE | 5 | ’<1: 603, ’no: 183, ’10: 103, ’50: 63 |
| employment | 0 | 1 | FALSE | 5 | ‘1<: 339,’>=: 253, ‘4<: 174,’<1: 172 |
| personal_status | 0 | 1 | FALSE | 4 | ’ma: 548, ’fe: 310, ’ma: 92, ’ma: 50 |
| other_parties | 0 | 1 | FALSE | 3 | non: 907, gua: 52, ’co: 41 |
| property_magnitude | 0 | 1 | FALSE | 4 | car: 332, ’re: 282, ’li: 232, ’no: 154 |
| other_payment_plans | 0 | 1 | FALSE | 3 | non: 814, ban: 139, sto: 47 |
| housing | 0 | 1 | FALSE | 3 | own: 713, ren: 179, ’fo: 108 |
| job | 0 | 1 | FALSE | 4 | ski: 630, ’un: 200, ’hi: 148, ’un: 22 |
| own_telephone | 0 | 1 | FALSE | 2 | non: 596, yes: 404 |
| foreign_worker | 0 | 1 | FALSE | 2 | yes: 963, no: 37 |
| class | 0 | 1 | FALSE | 2 | goo: 700, bad: 300 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 |
|---|---|---|---|---|---|---|---|---|---|
| duration | 0 | 1 | 20.90 | 12.06 | 4 | 12.0 | 18.0 | 24.00 | 72 |
| credit_amount | 0 | 1 | 3271.26 | 2822.74 | 250 | 1365.5 | 2319.5 | 3972.25 | 18424 |
| installment_commitment | 0 | 1 | 2.97 | 1.12 | 1 | 2.0 | 3.0 | 4.00 | 4 |
| residence_since | 0 | 1 | 2.85 | 1.10 | 1 | 2.0 | 3.0 | 4.00 | 4 |
| age | 0 | 1 | 35.55 | 11.38 | 19 | 27.0 | 33.0 | 42.00 | 75 |
| existing_credits | 0 | 1 | 1.41 | 0.58 | 1 | 1.0 | 1.0 | 2.00 | 4 |
| num_dependents | 0 | 1 | 1.16 | 0.36 | 1 | 1.0 | 1.0 | 1.00 | 2 |
Distribusi Variabel Kategorik
df %>%
ExpCatViz(clim = 10,
col = "#107896",
Page = NULL,
Flip = TRUE)[[1]]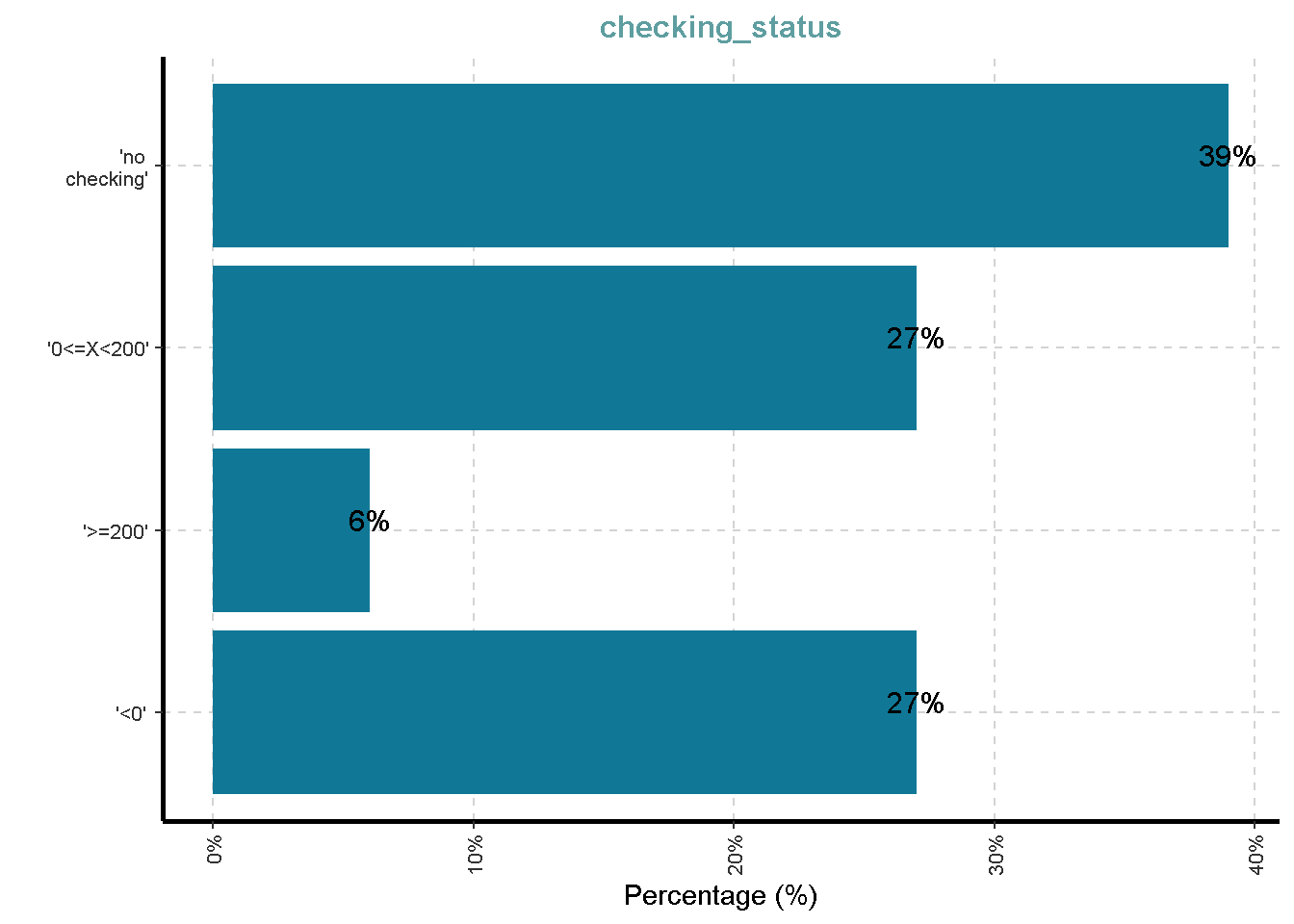
[[2]]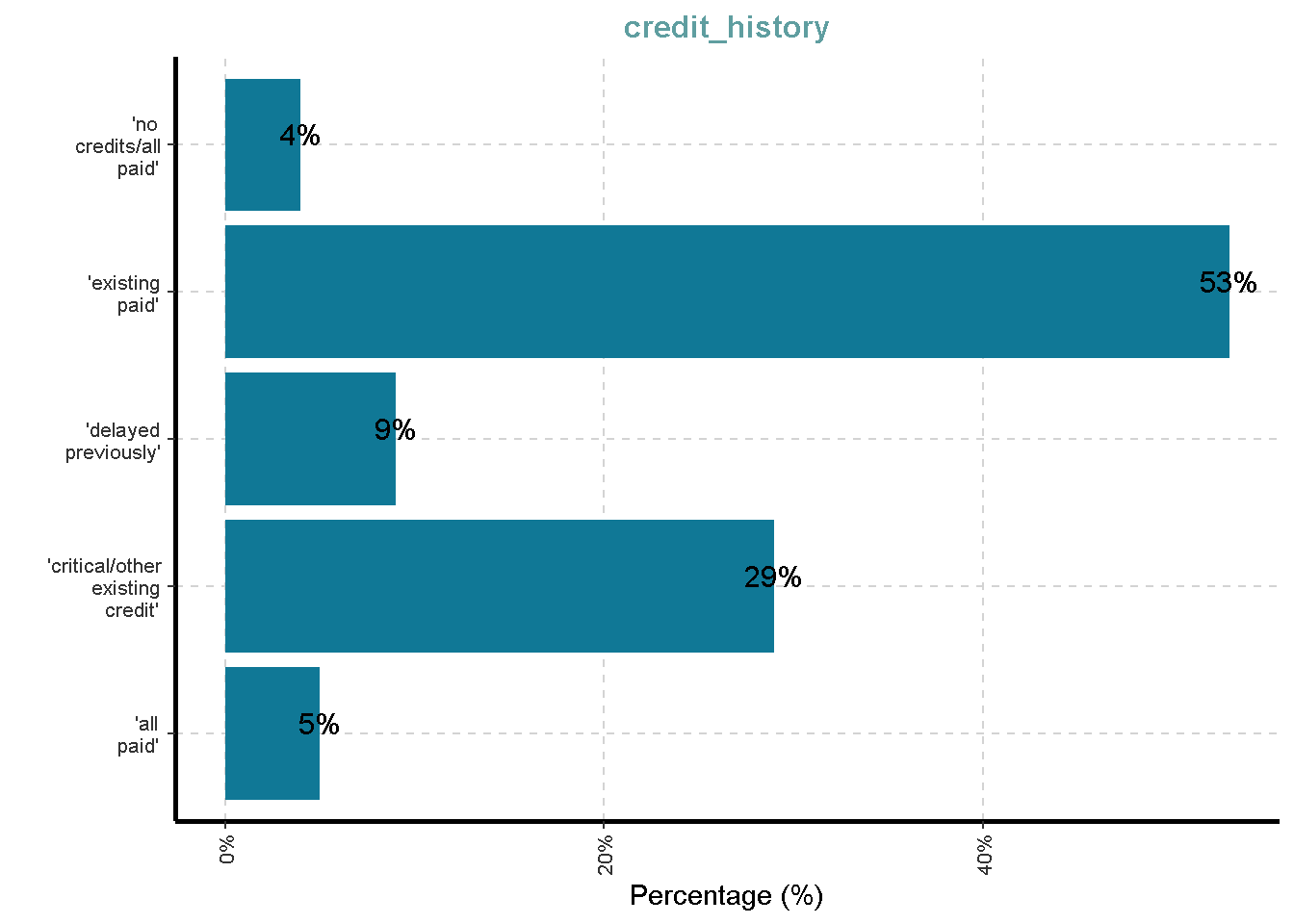
[[3]]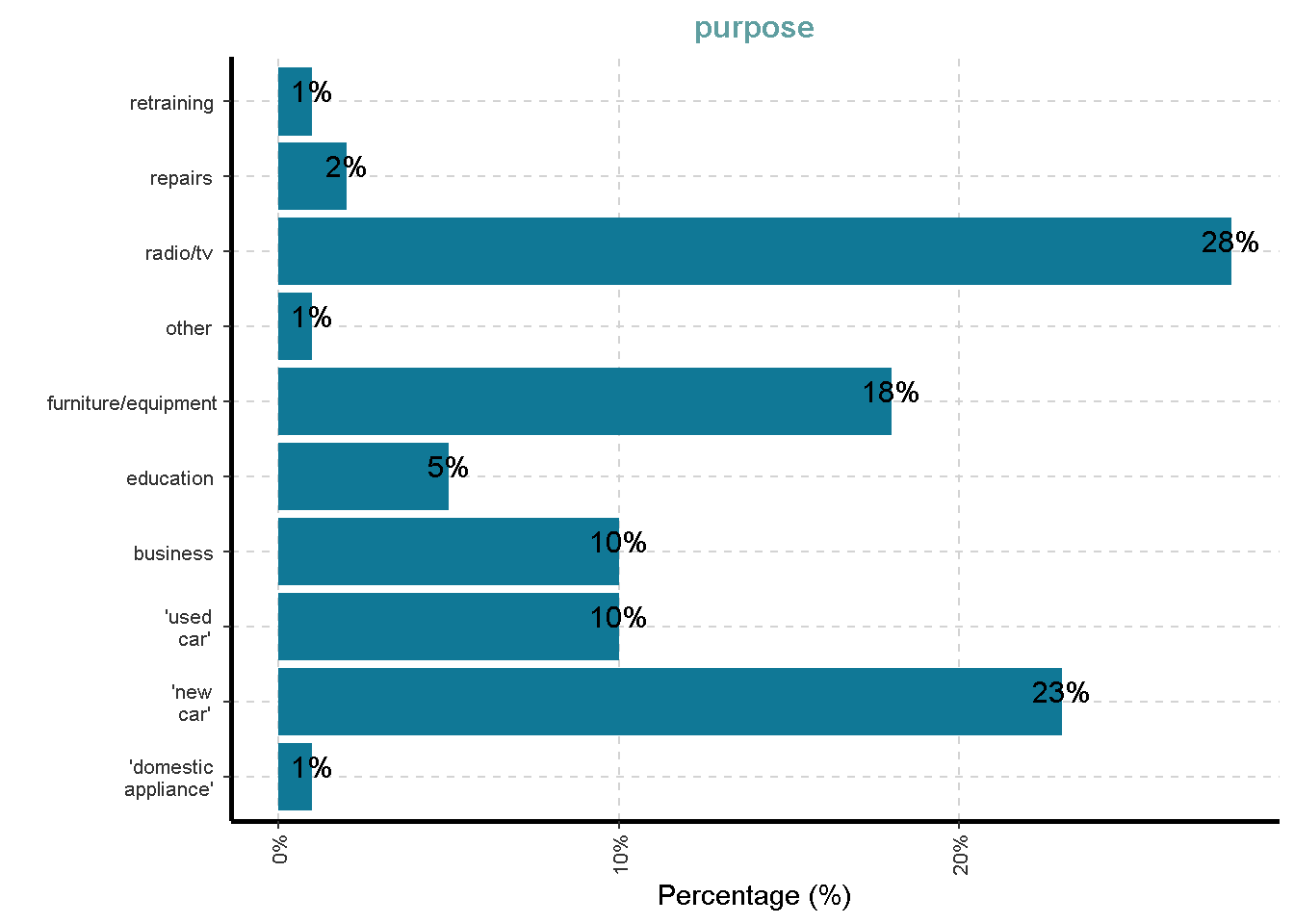
[[4]]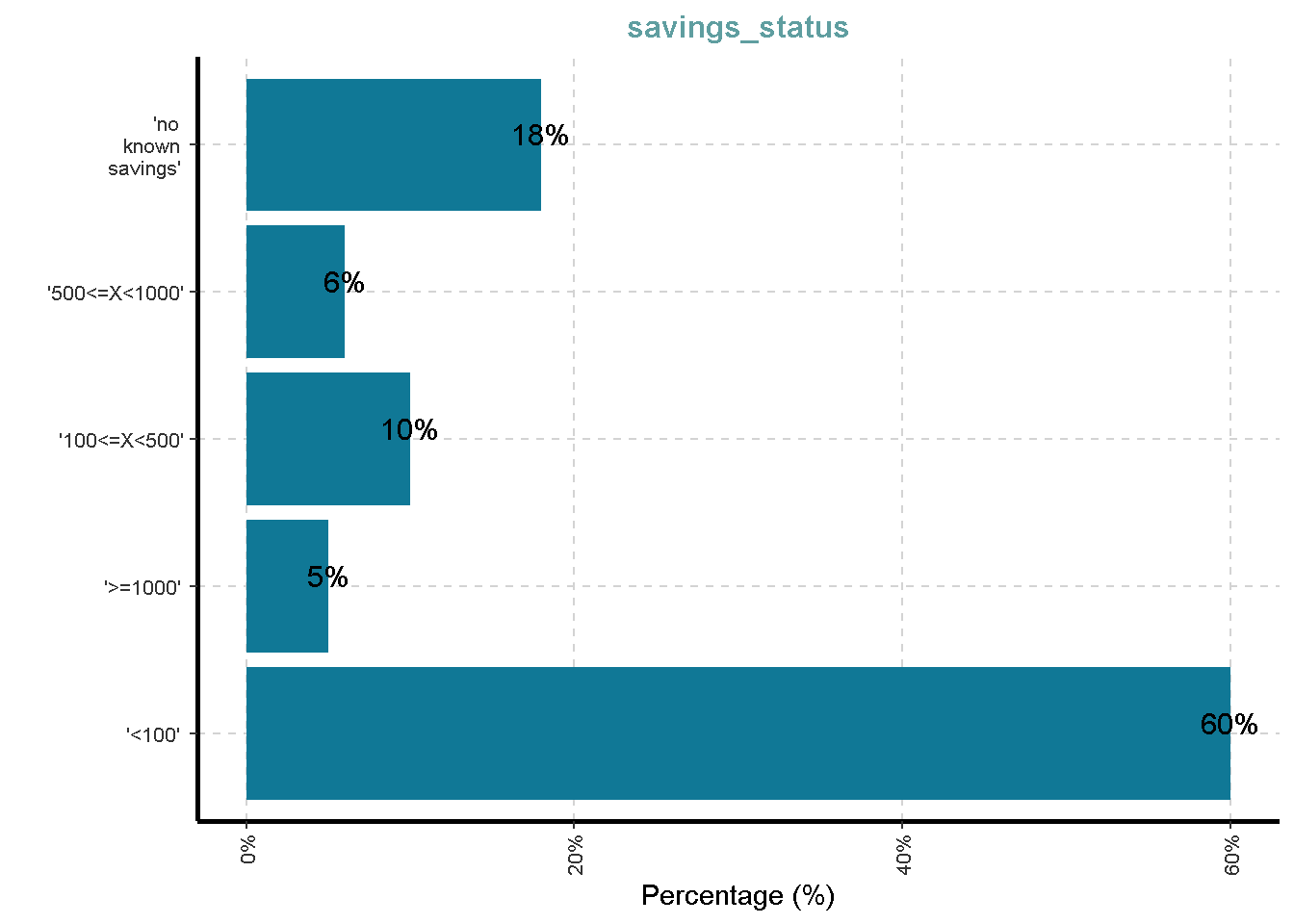
[[5]]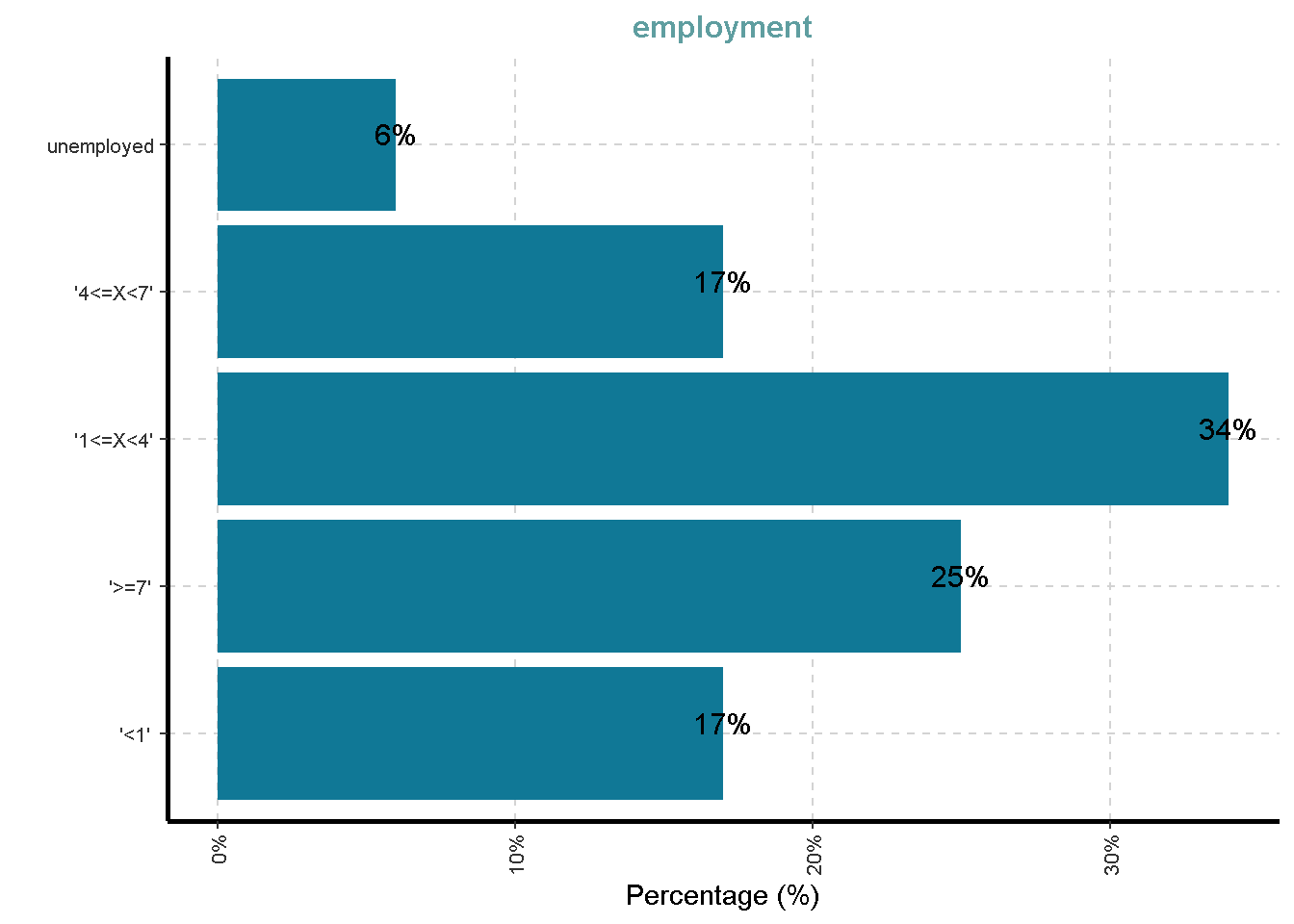
[[6]]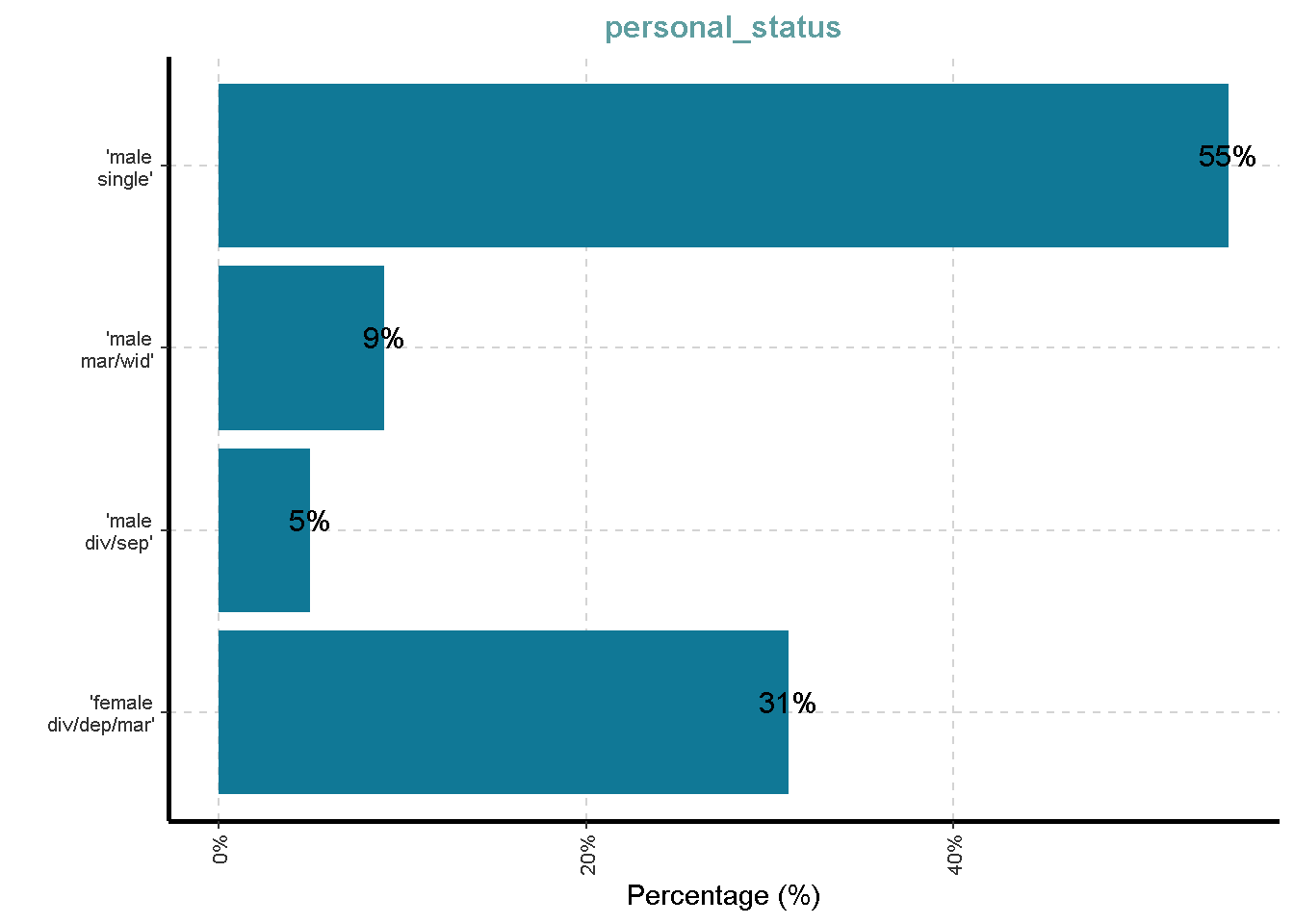
[[7]]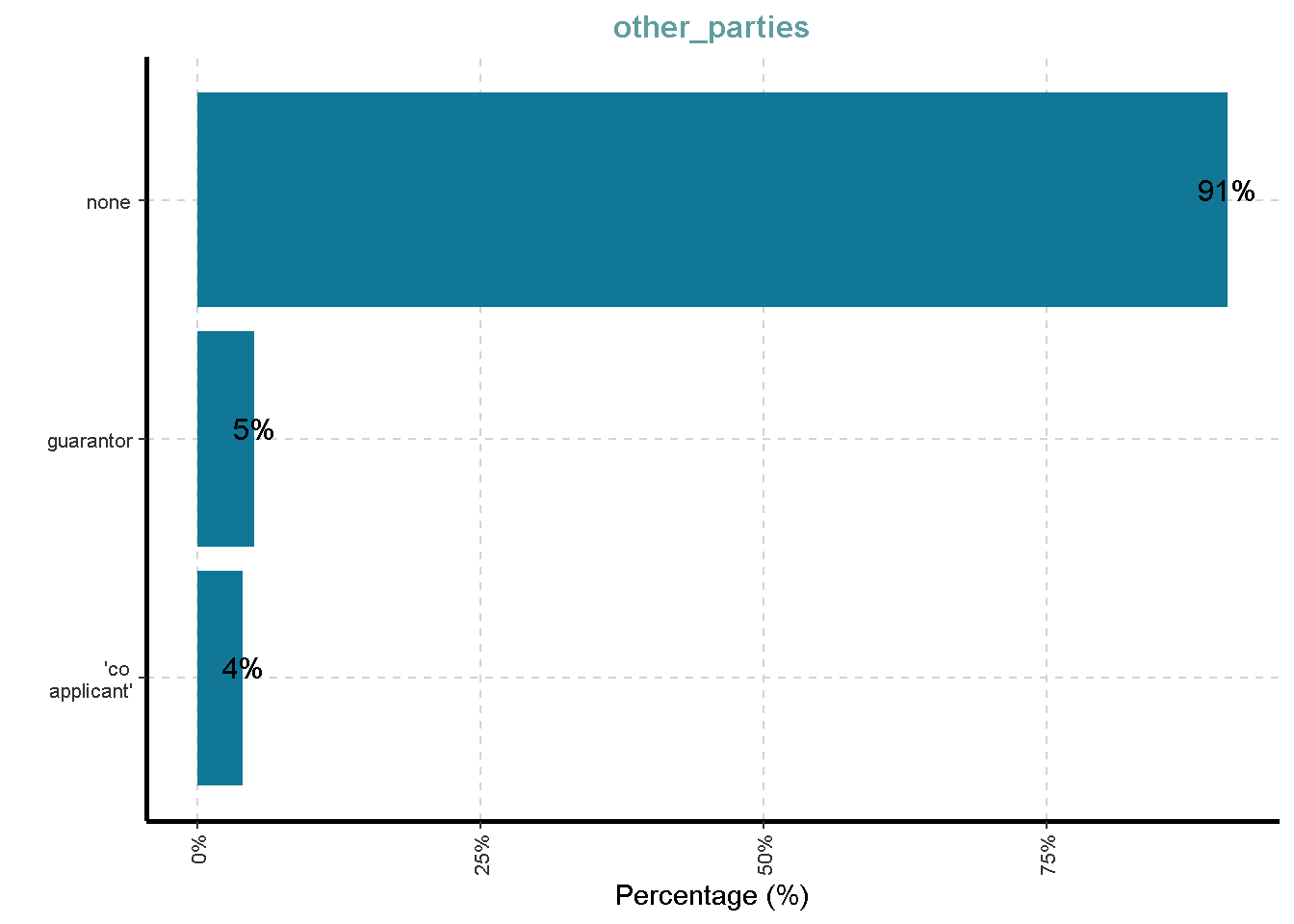
[[8]]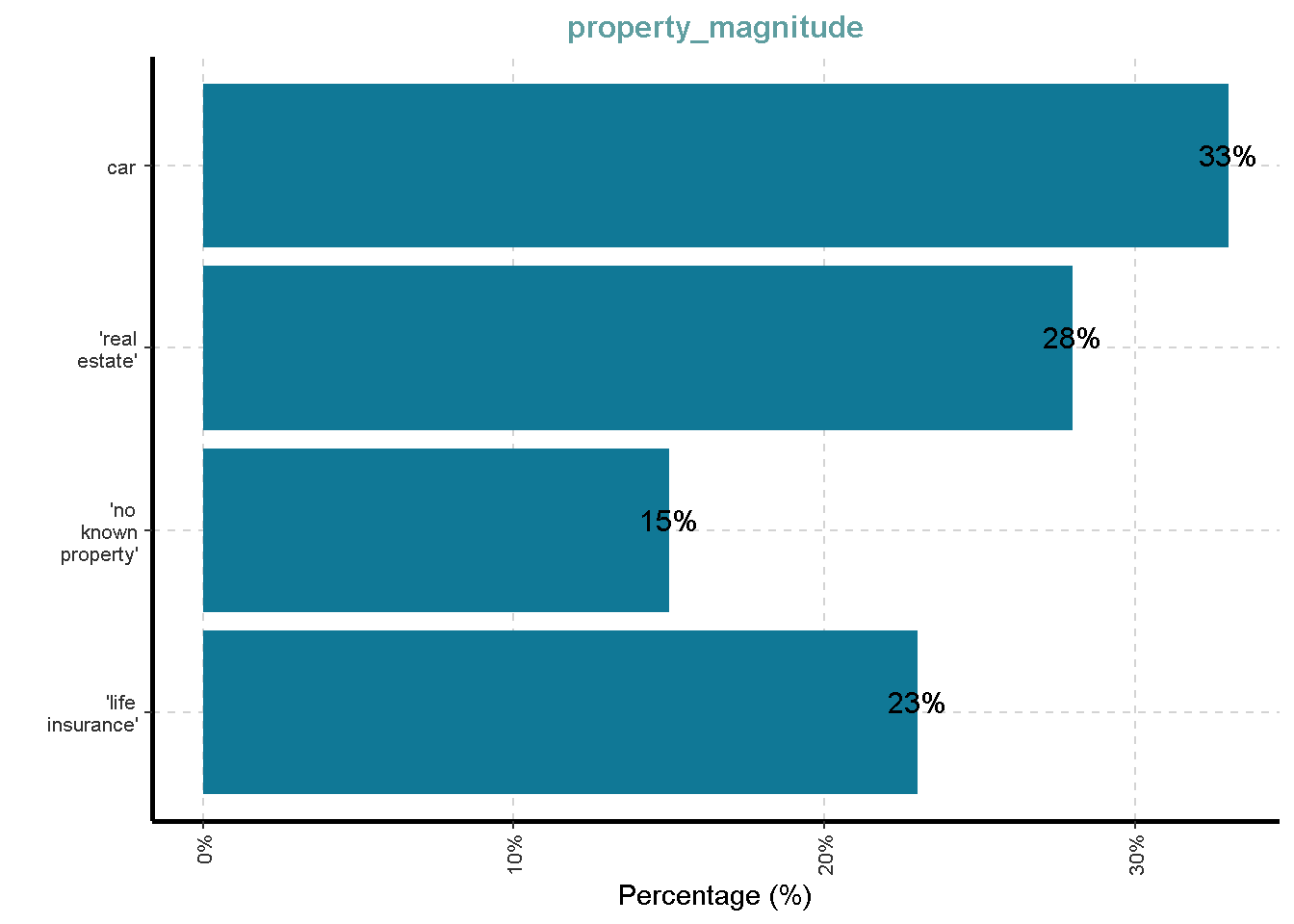
[[9]]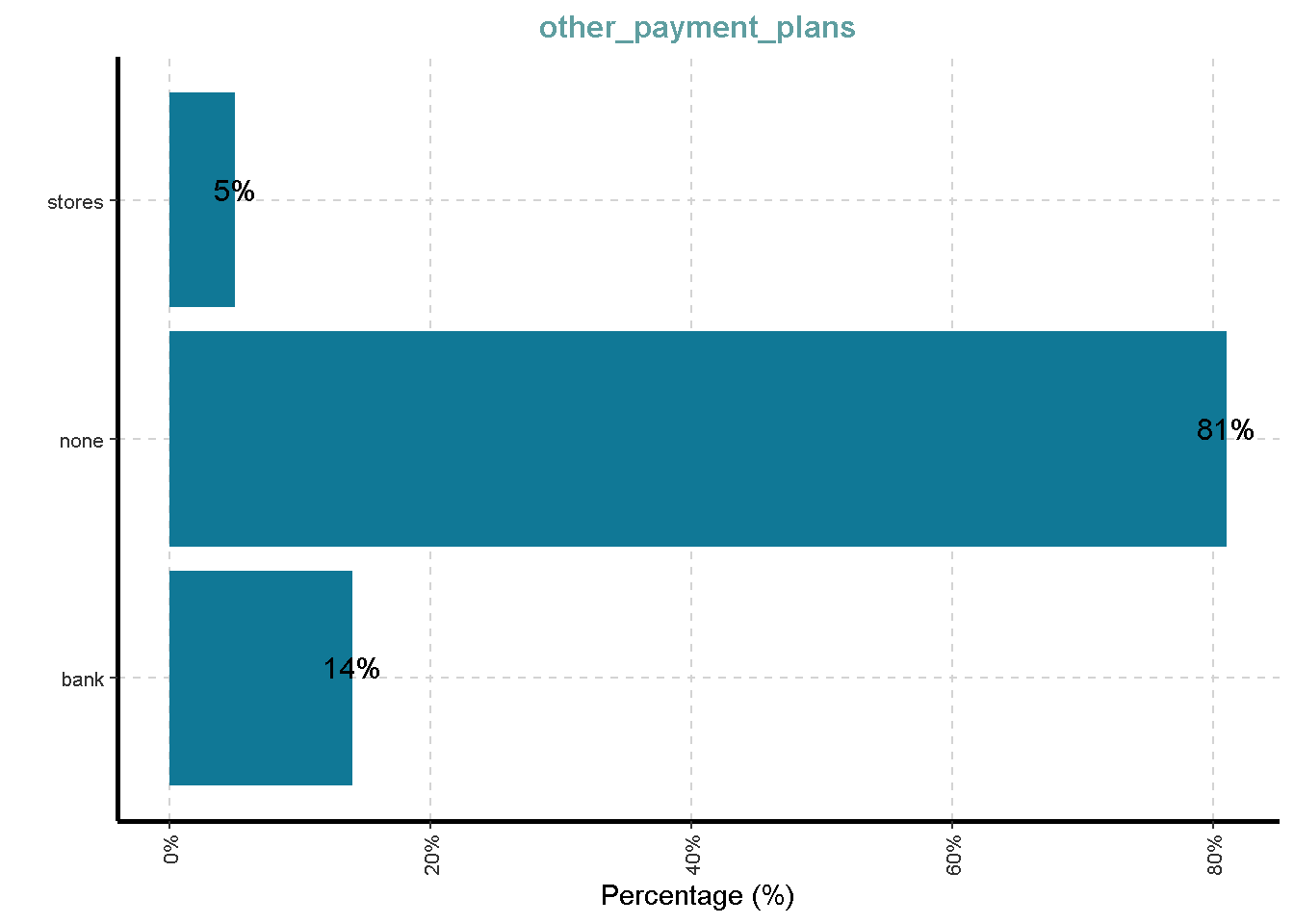
[[10]]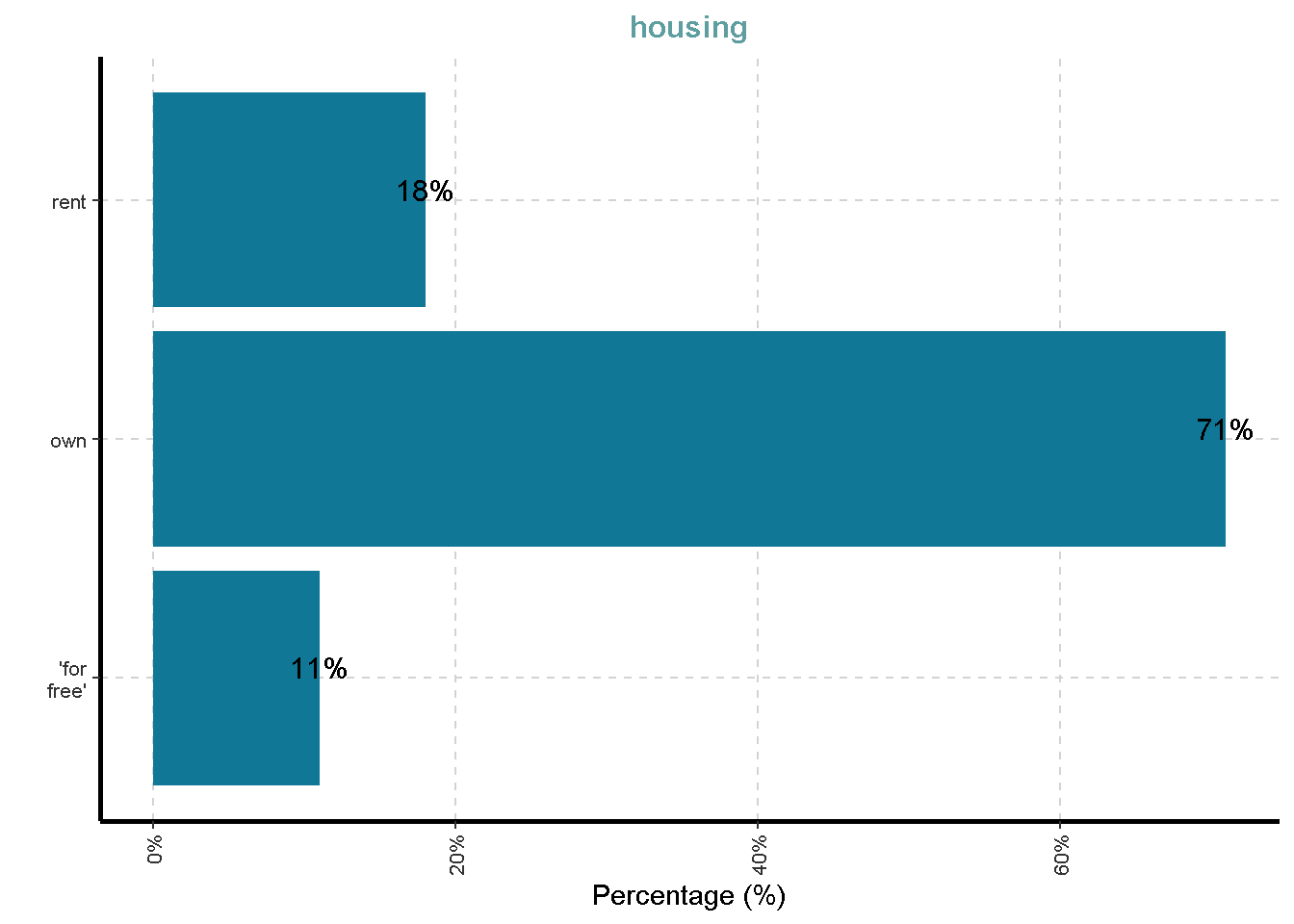
[[11]]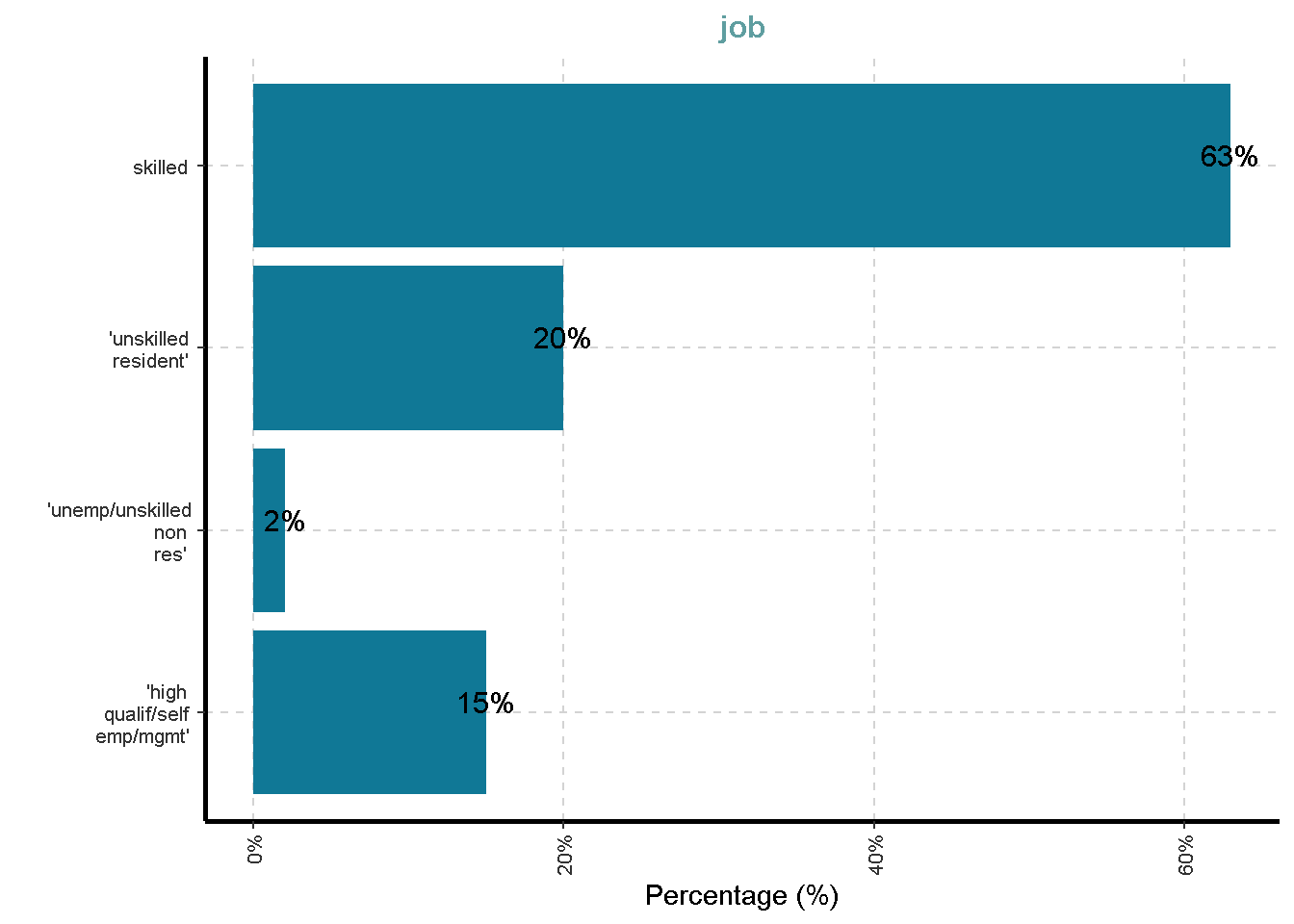
[[12]]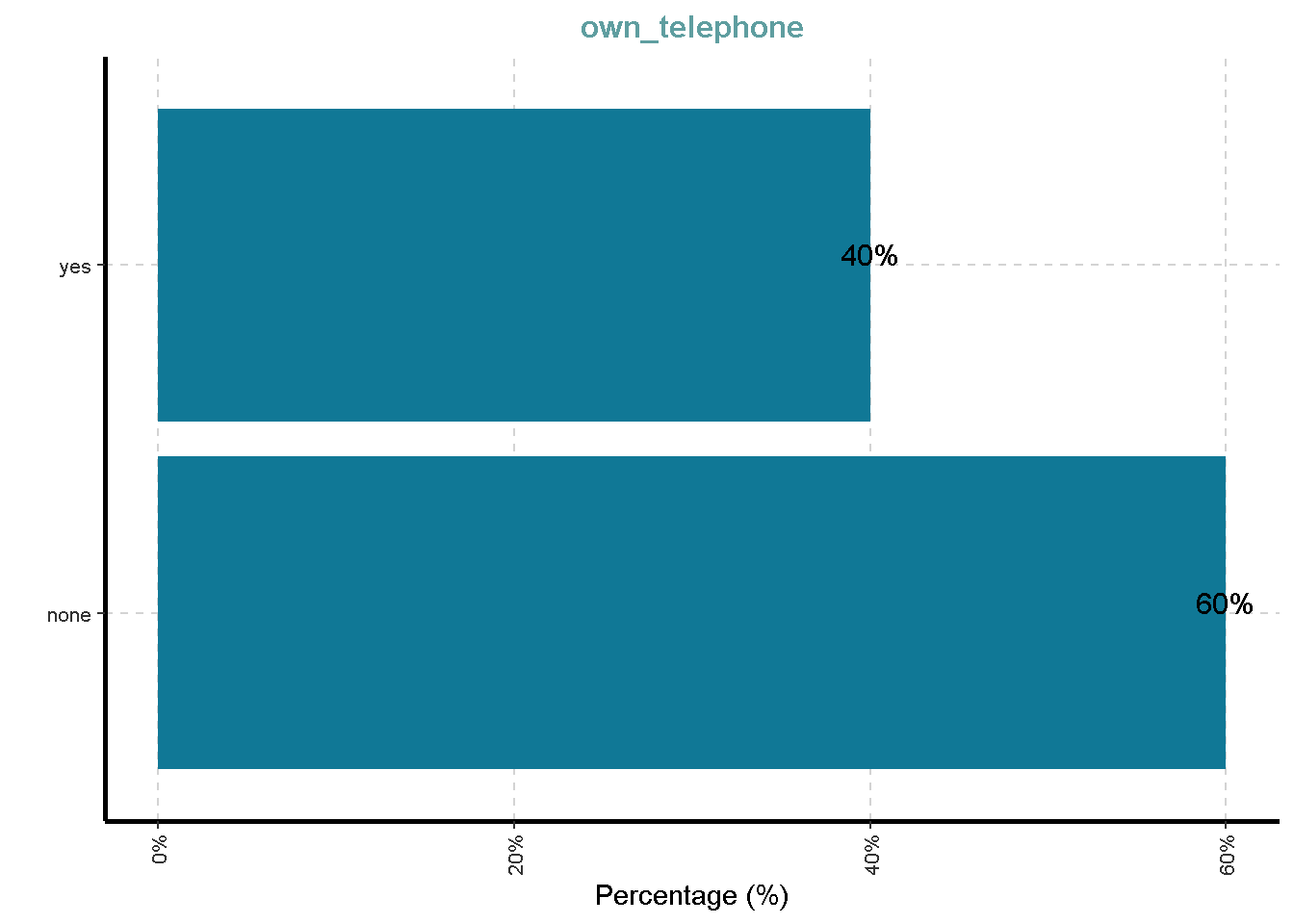
[[13]]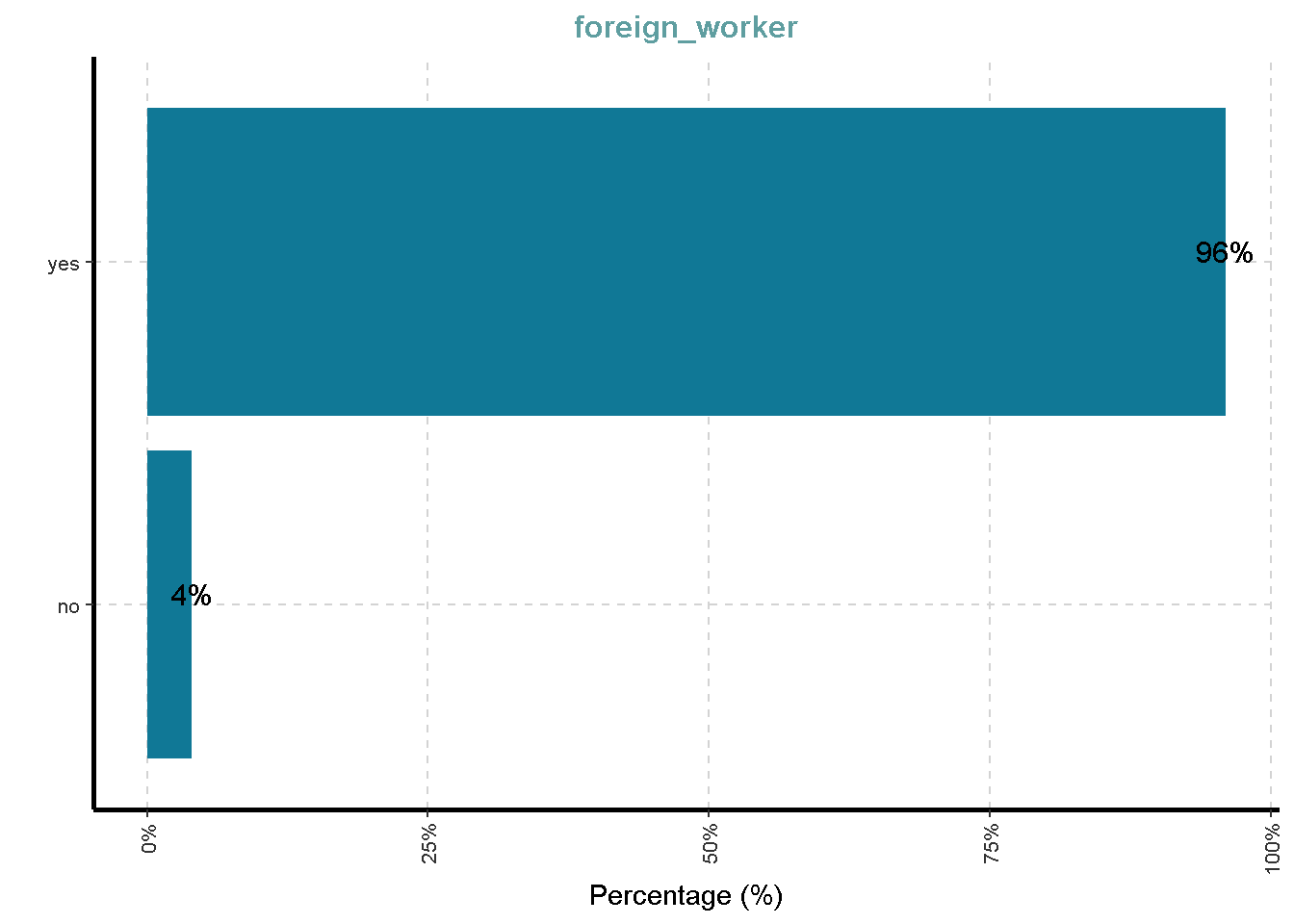
[[14]]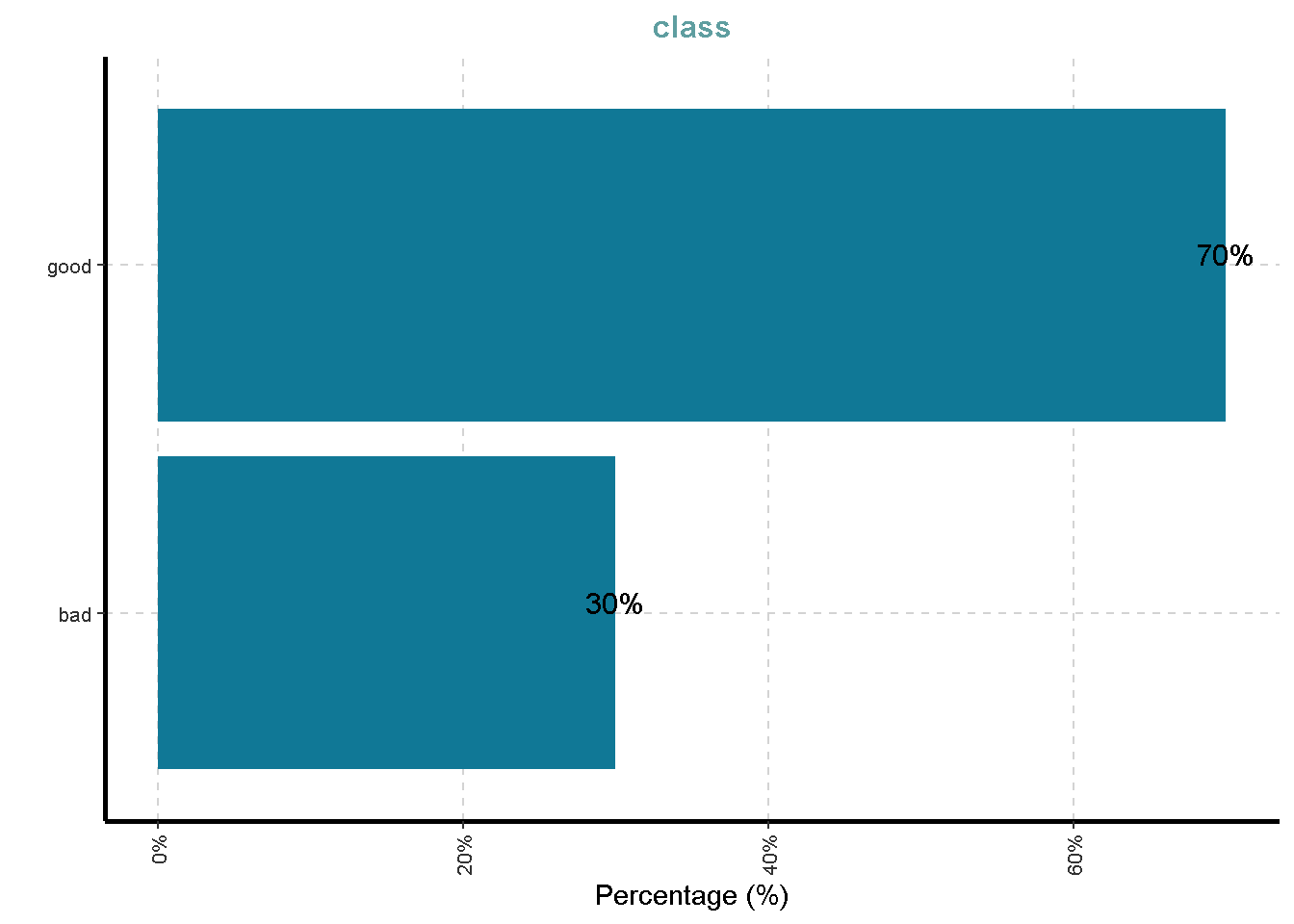
[[15]]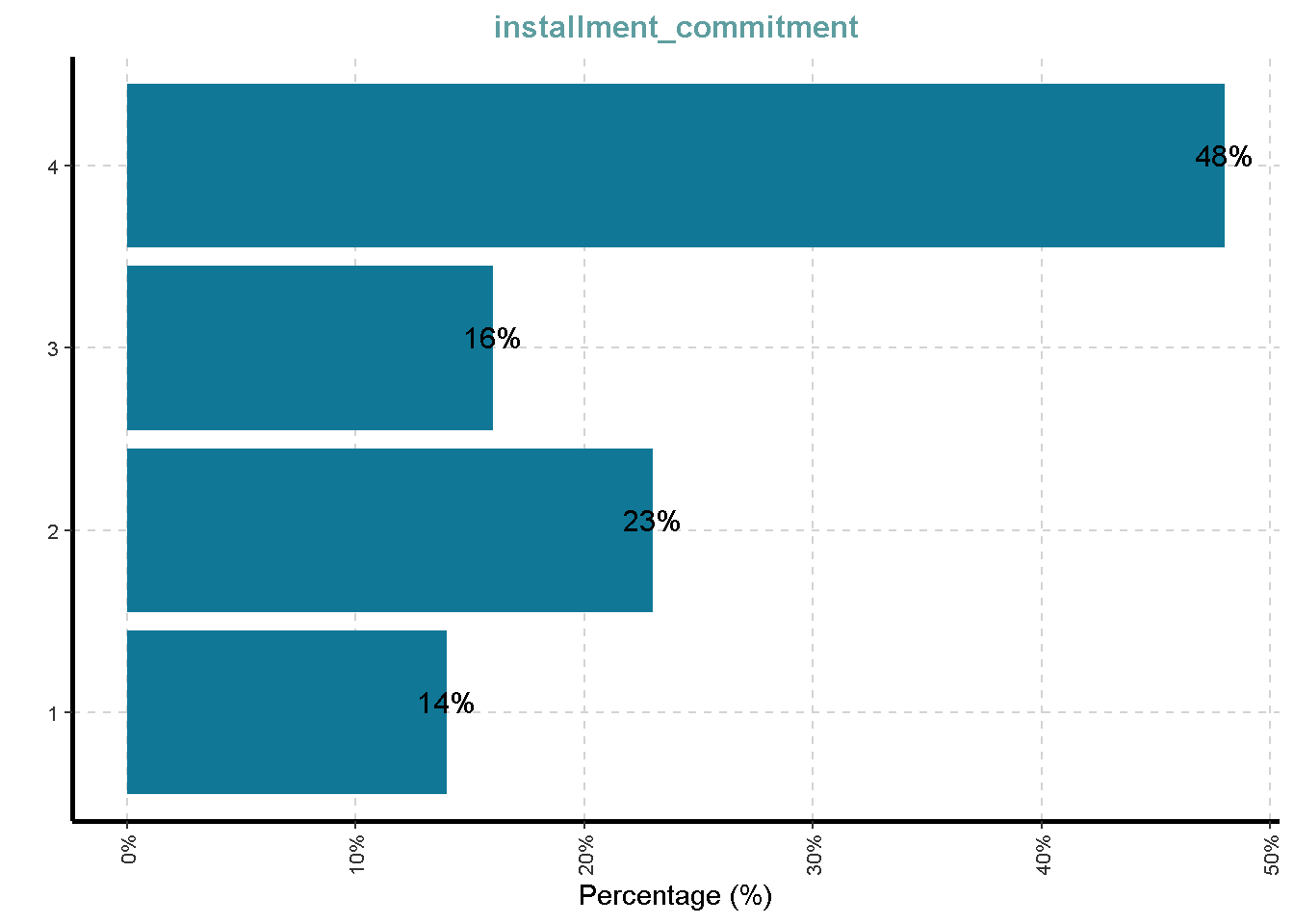
[[16]]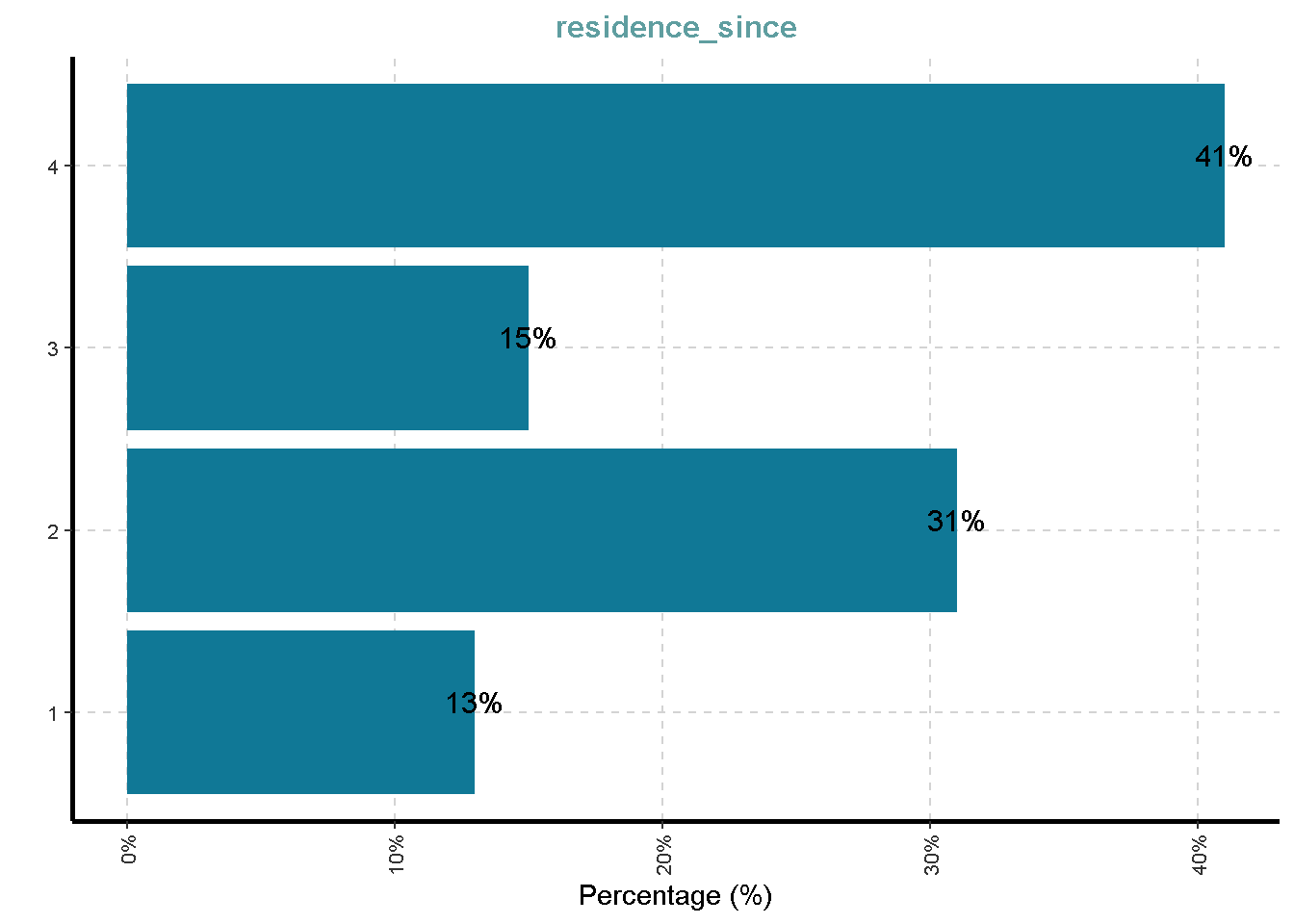
[[17]]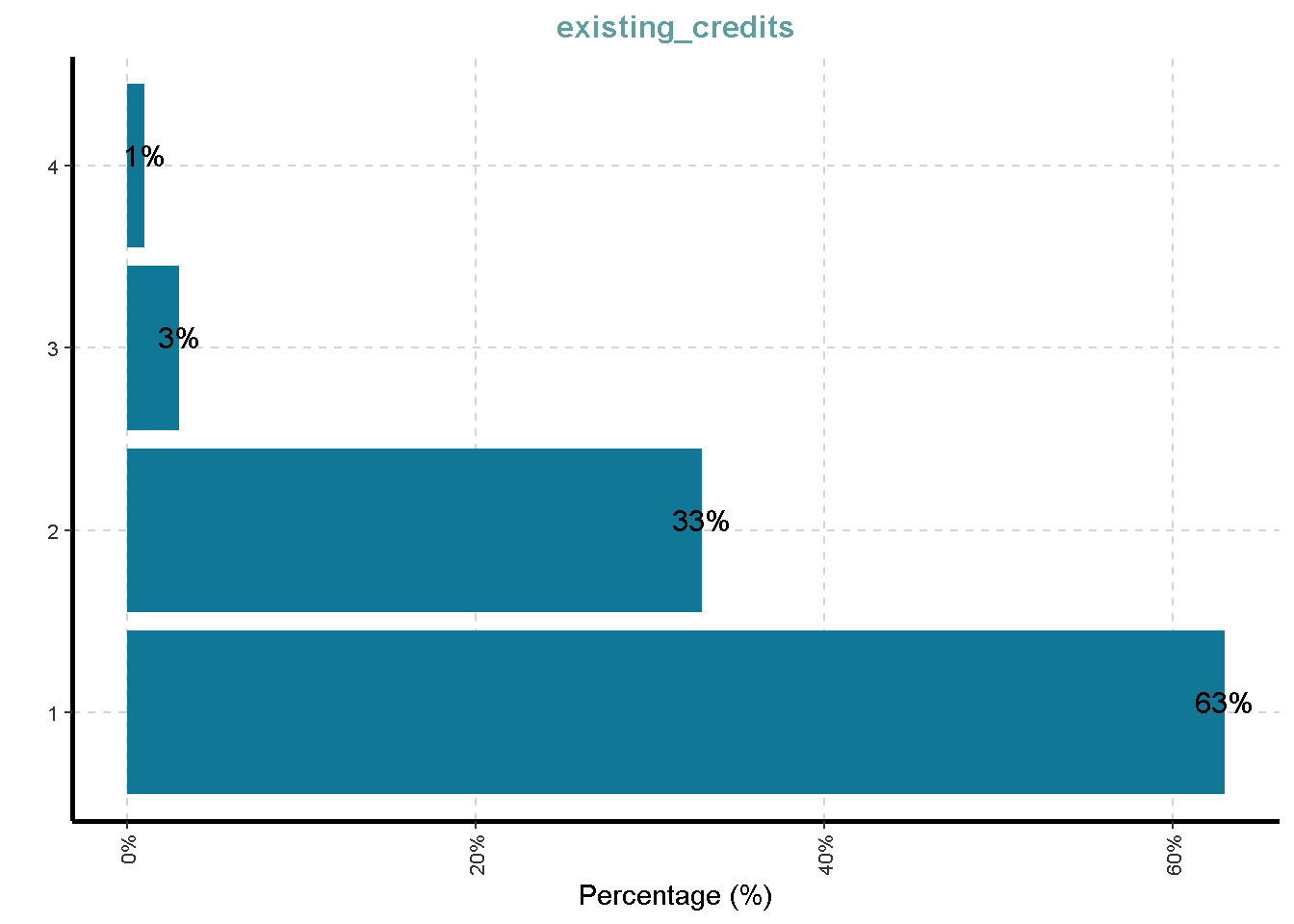
[[18]]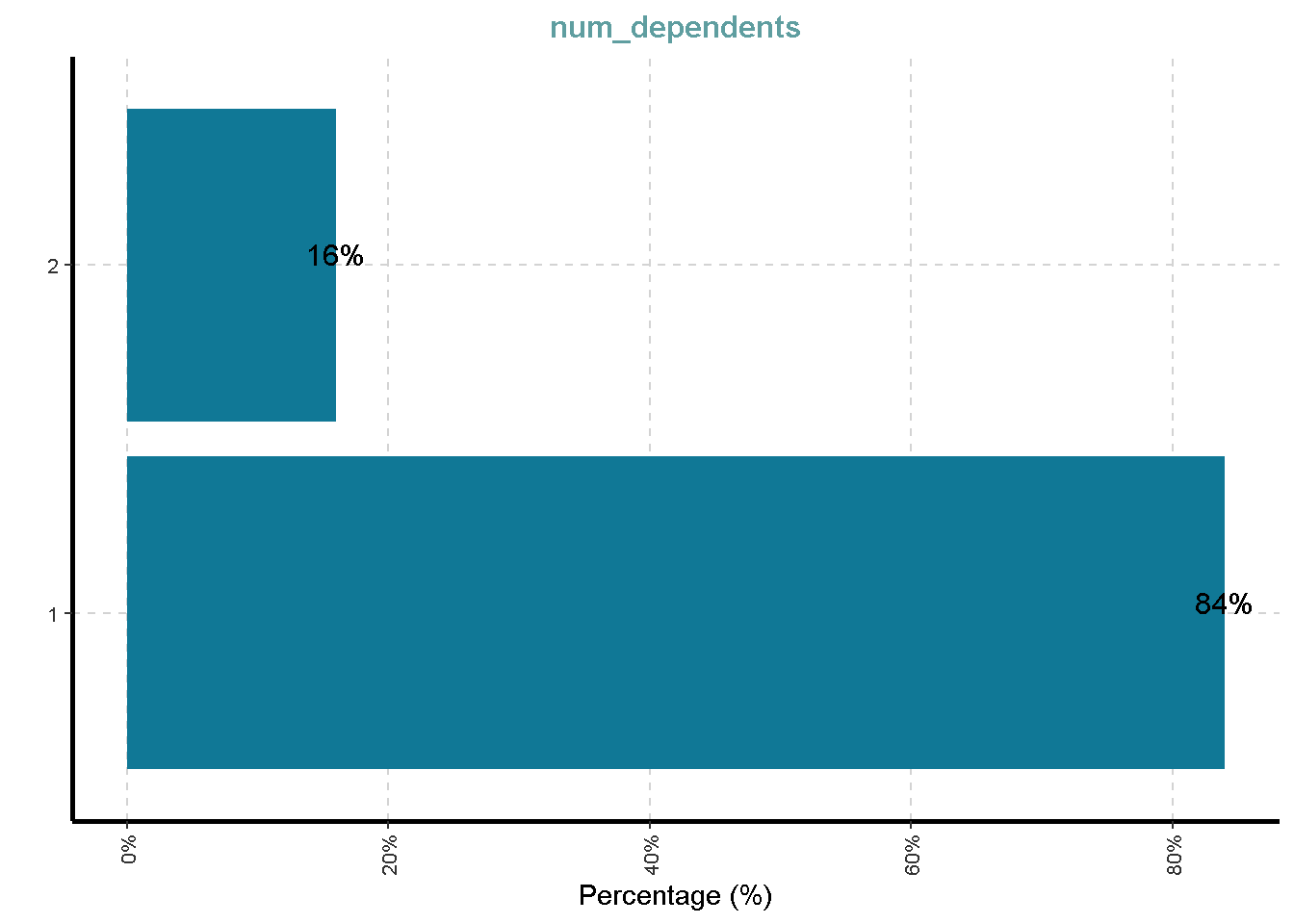
Distribusi Variabel Numerik
df %>%
plot_histogram(
ggtheme = theme_lares(),
geom_histogram_args = list(bins=30,
col="black",
fill="#107896"),
ncol = 1,nrow = 1)Warning in .font_global(font, quiet = FALSE, ...): Font(s) "Arial Narrow" not
installed, with other name, or can't be found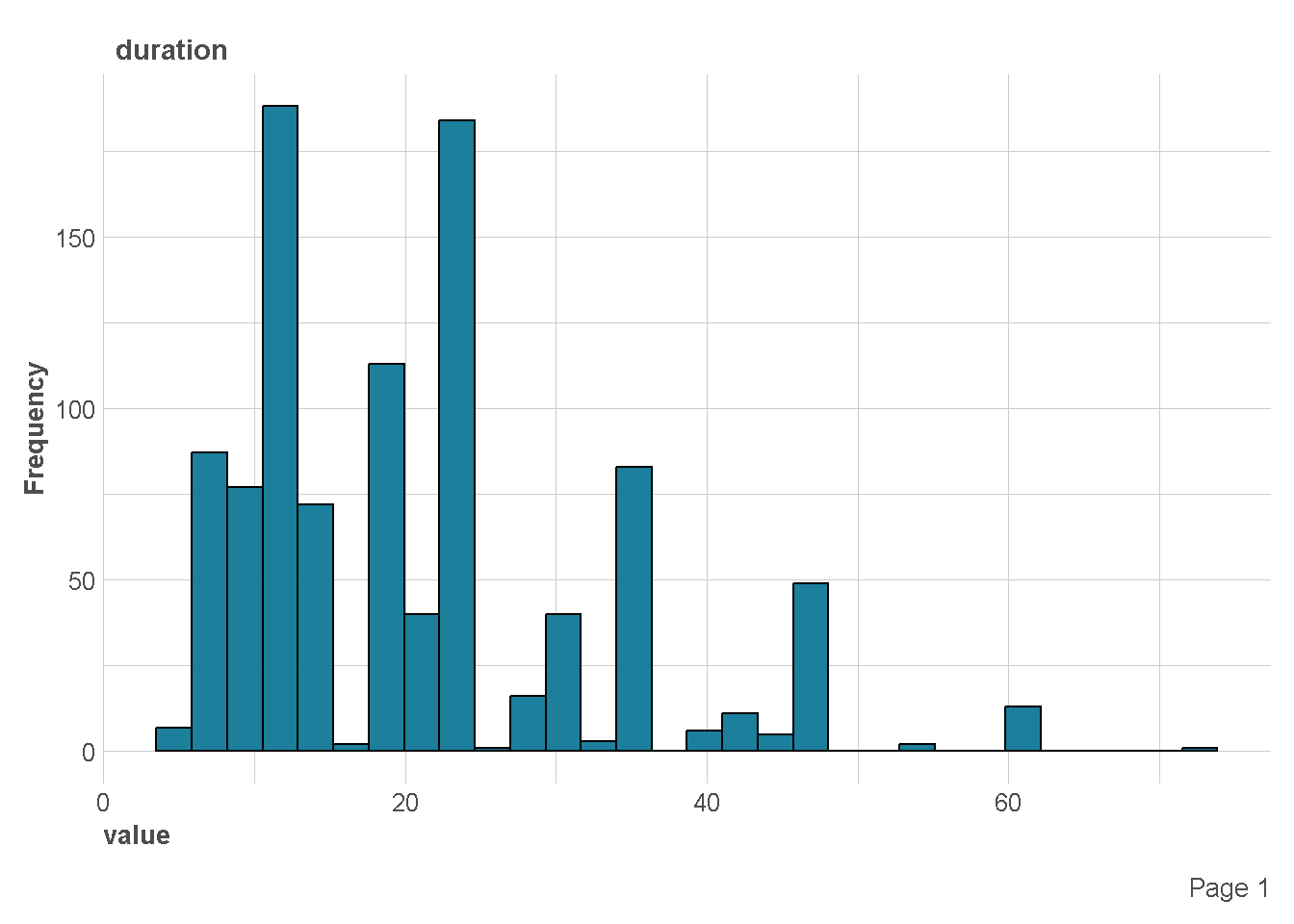
Ekplorasi Kategorik vs Kategorik
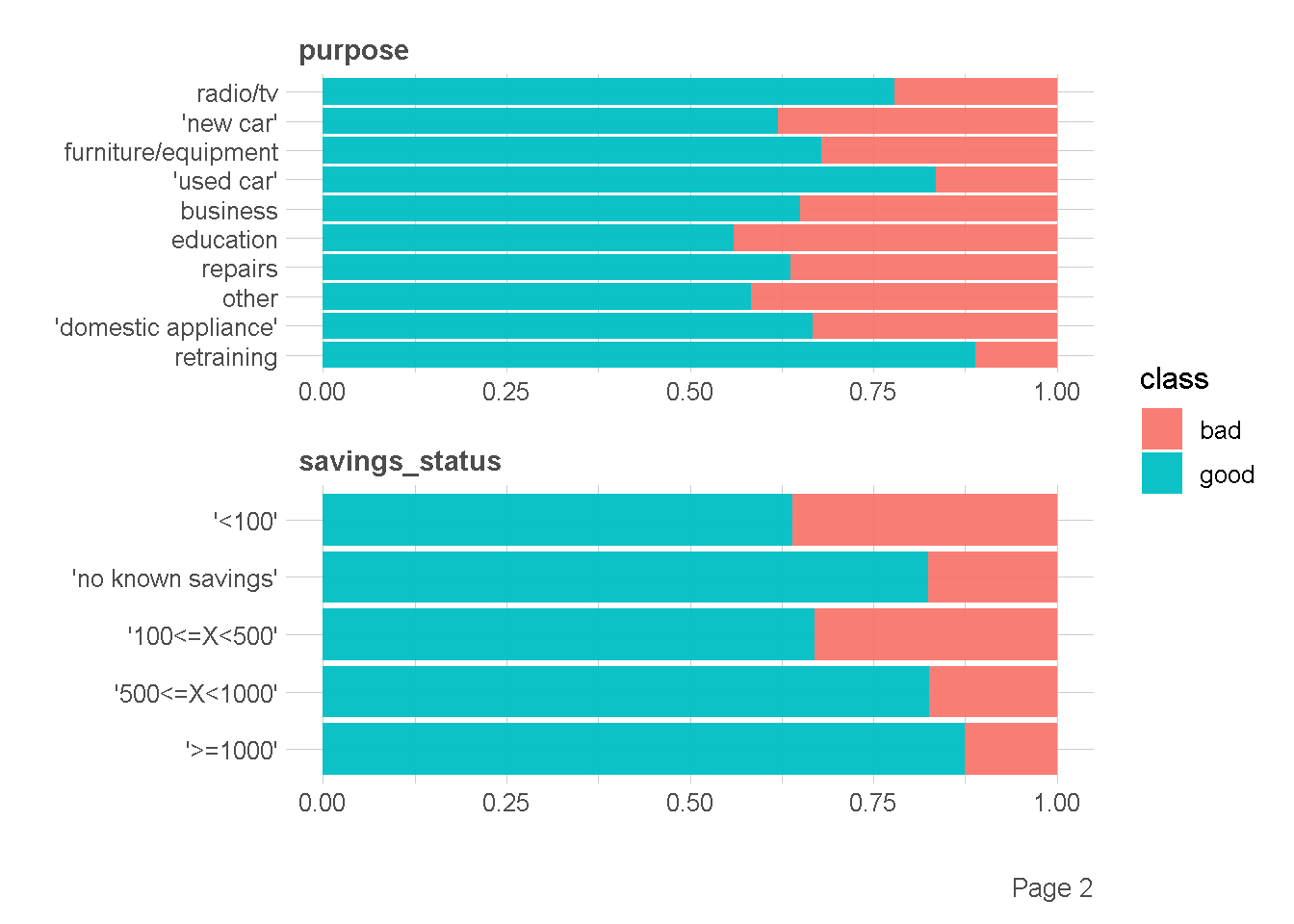
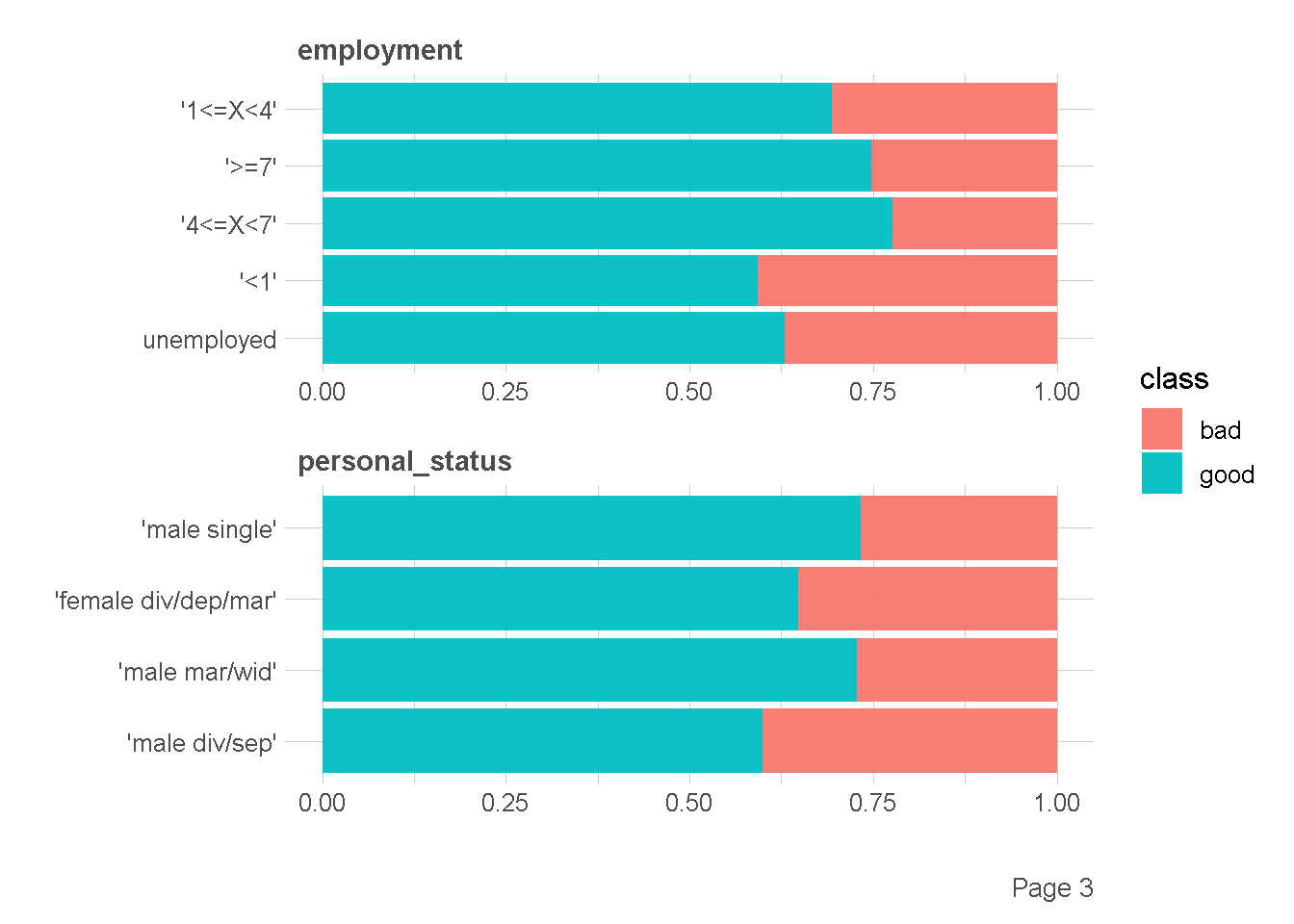
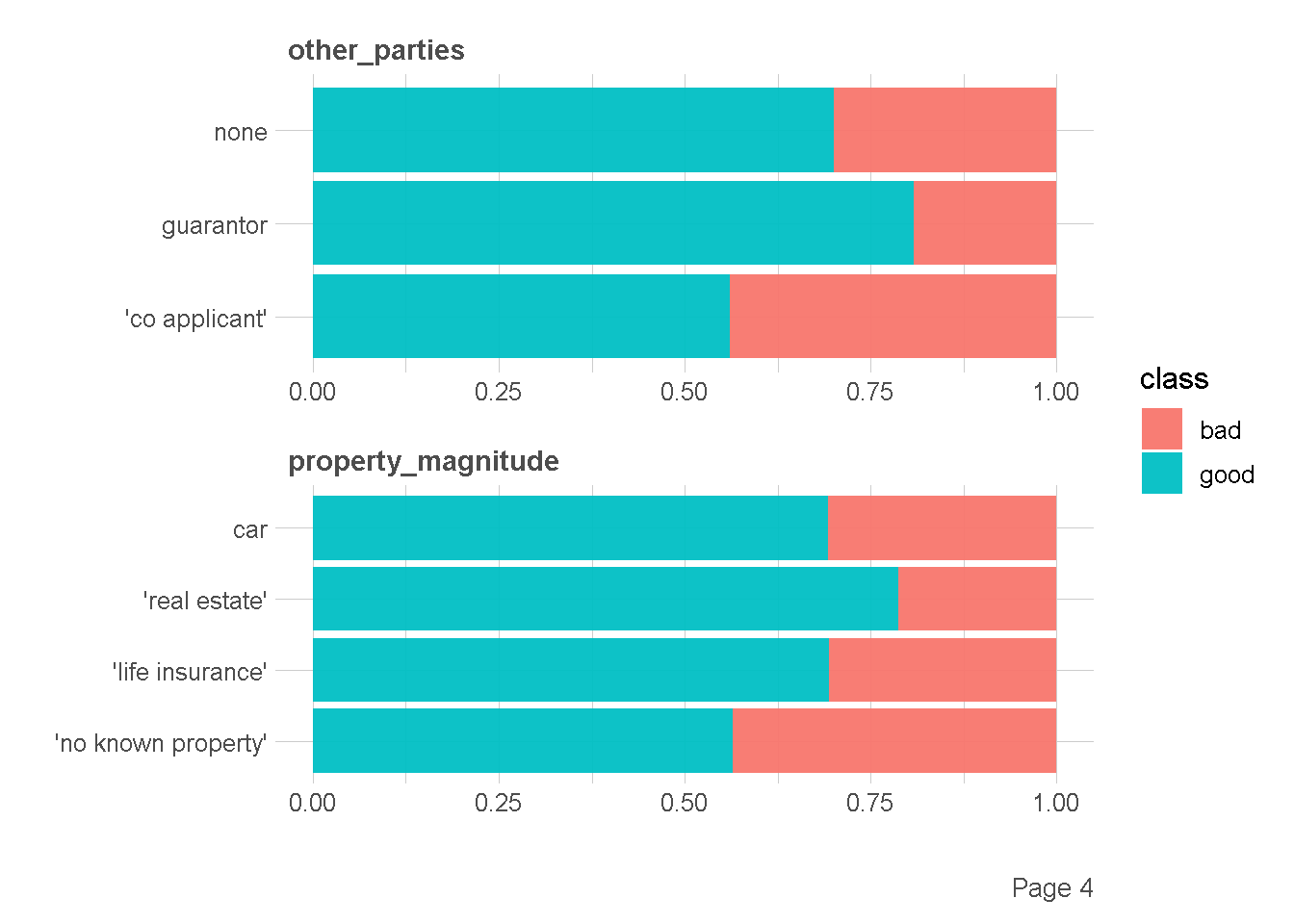
df %>%
plot_bar(by = "class",
ggtheme = theme_lares(),
nrow = 2,ncol = 1
)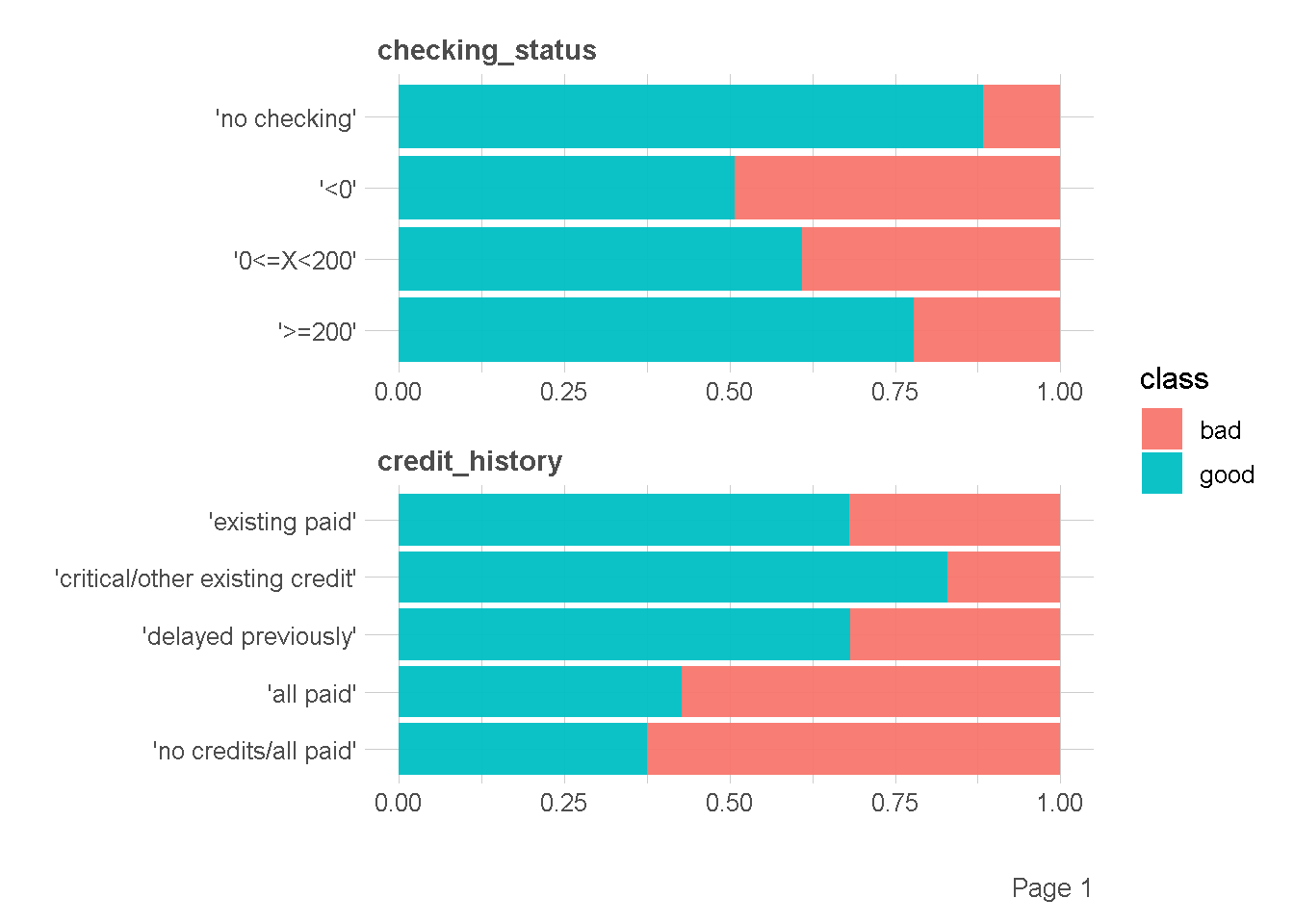
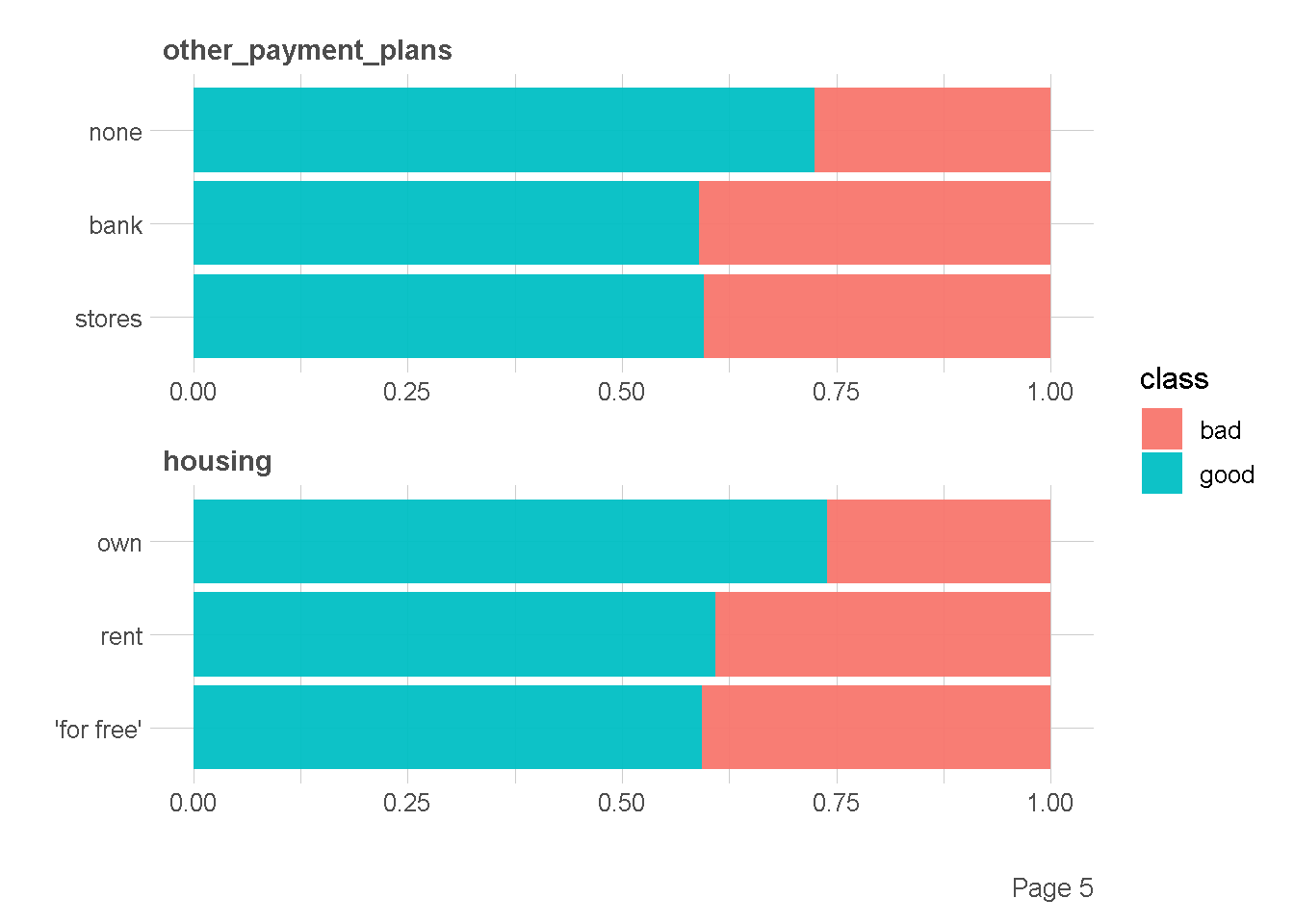
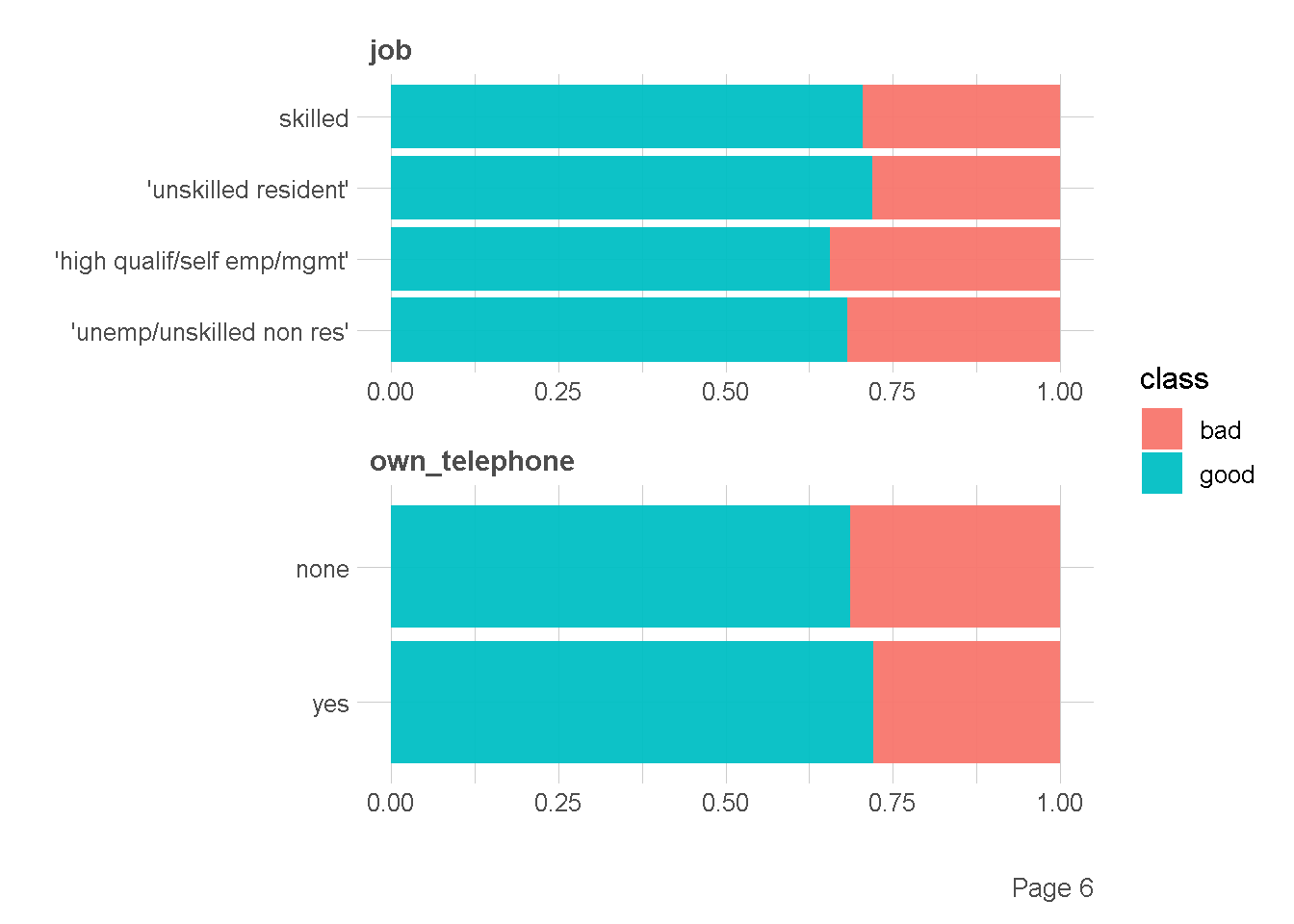
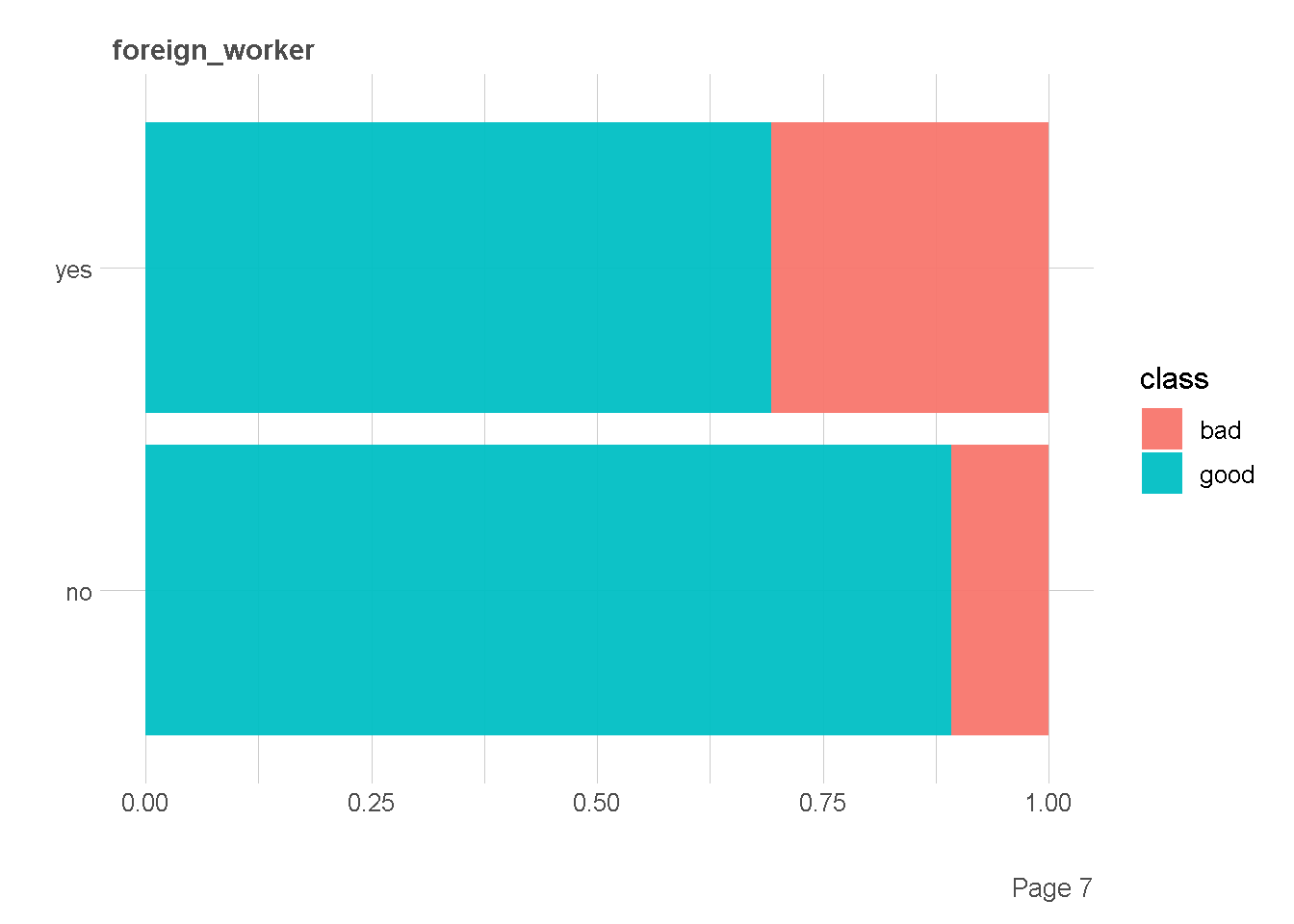
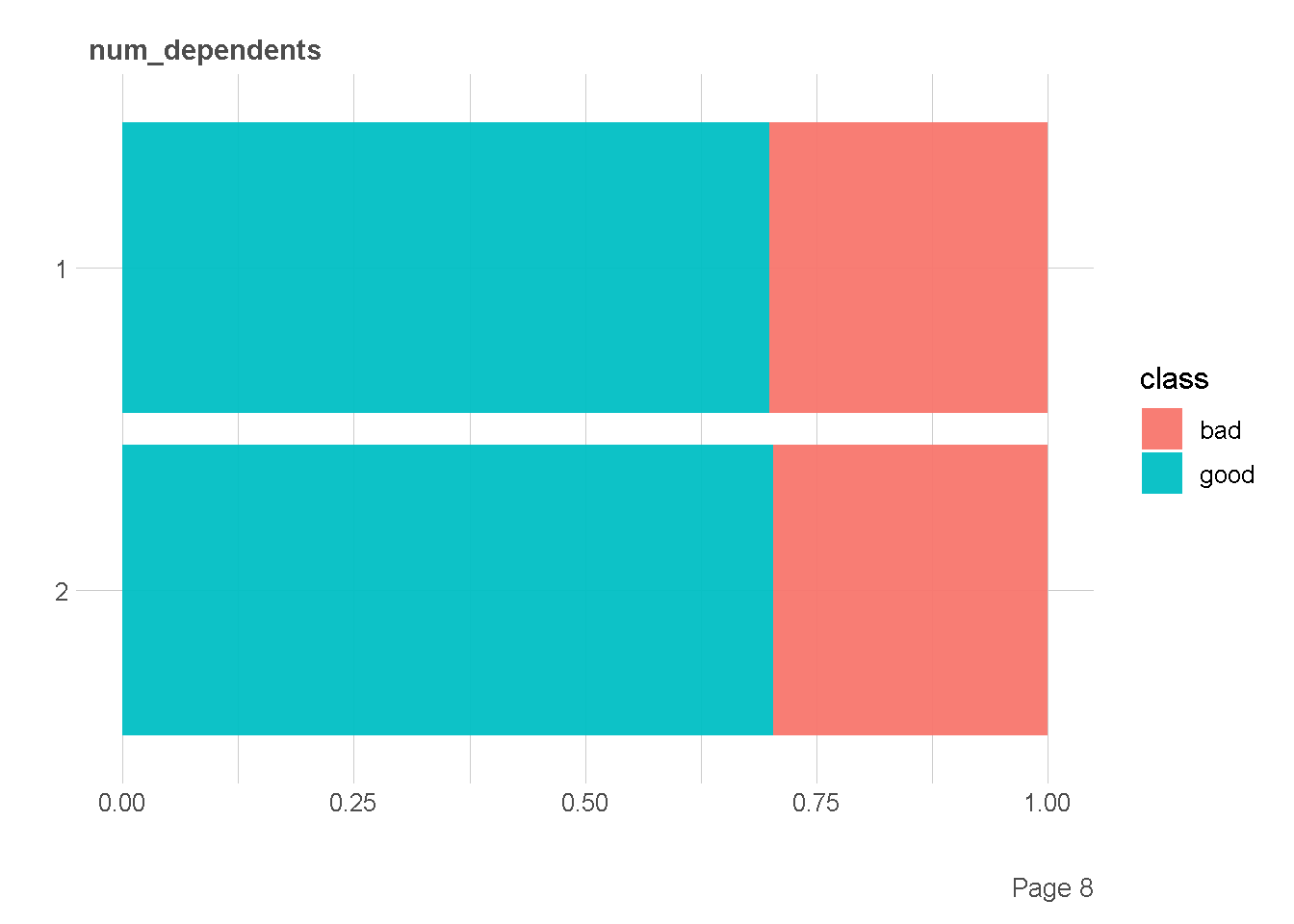
Ekplorasi Kategorik vs Numerik
df %>%
ExpNumViz(target = "class",
type = 2)[[1]]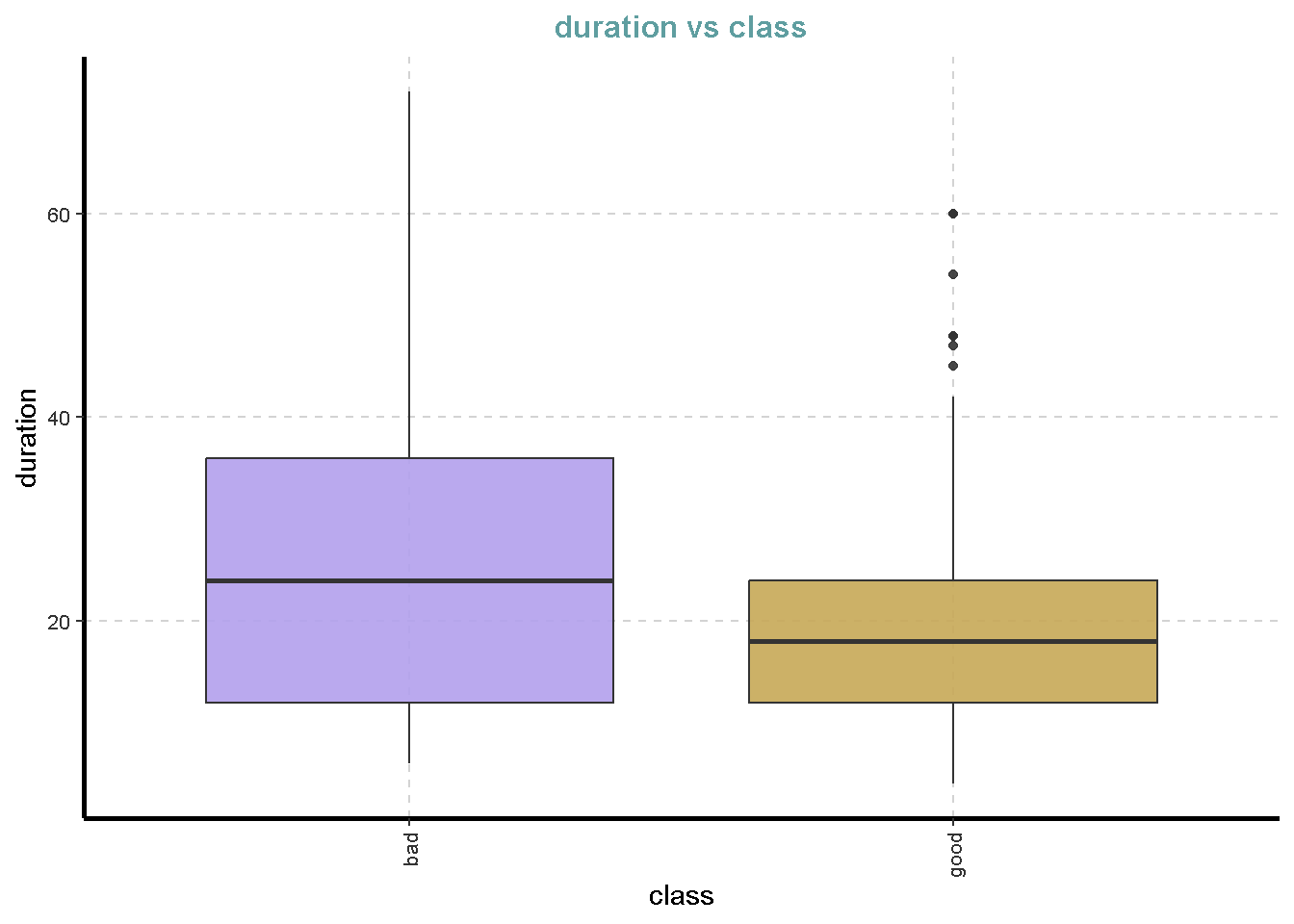
[[2]]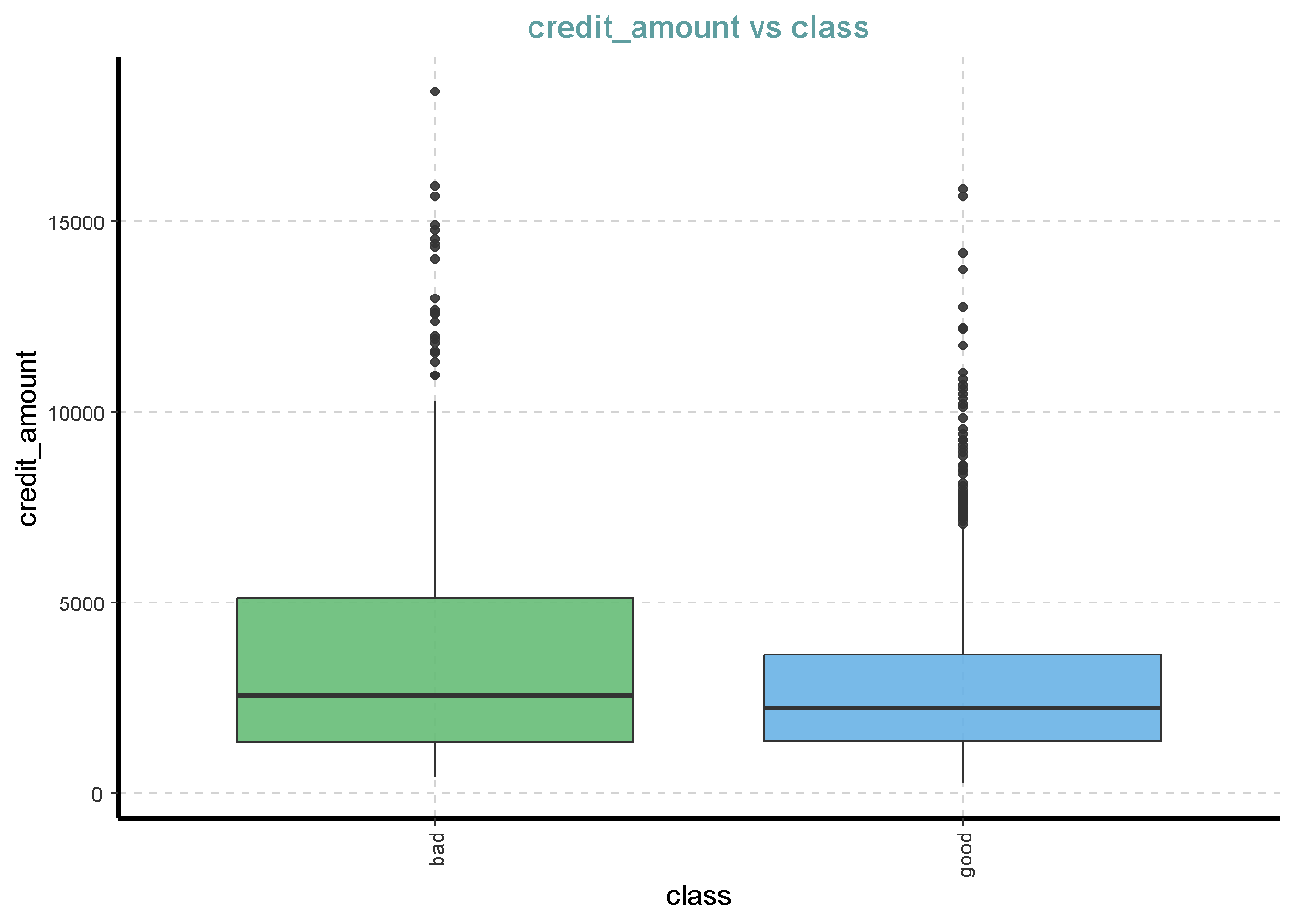
[[3]]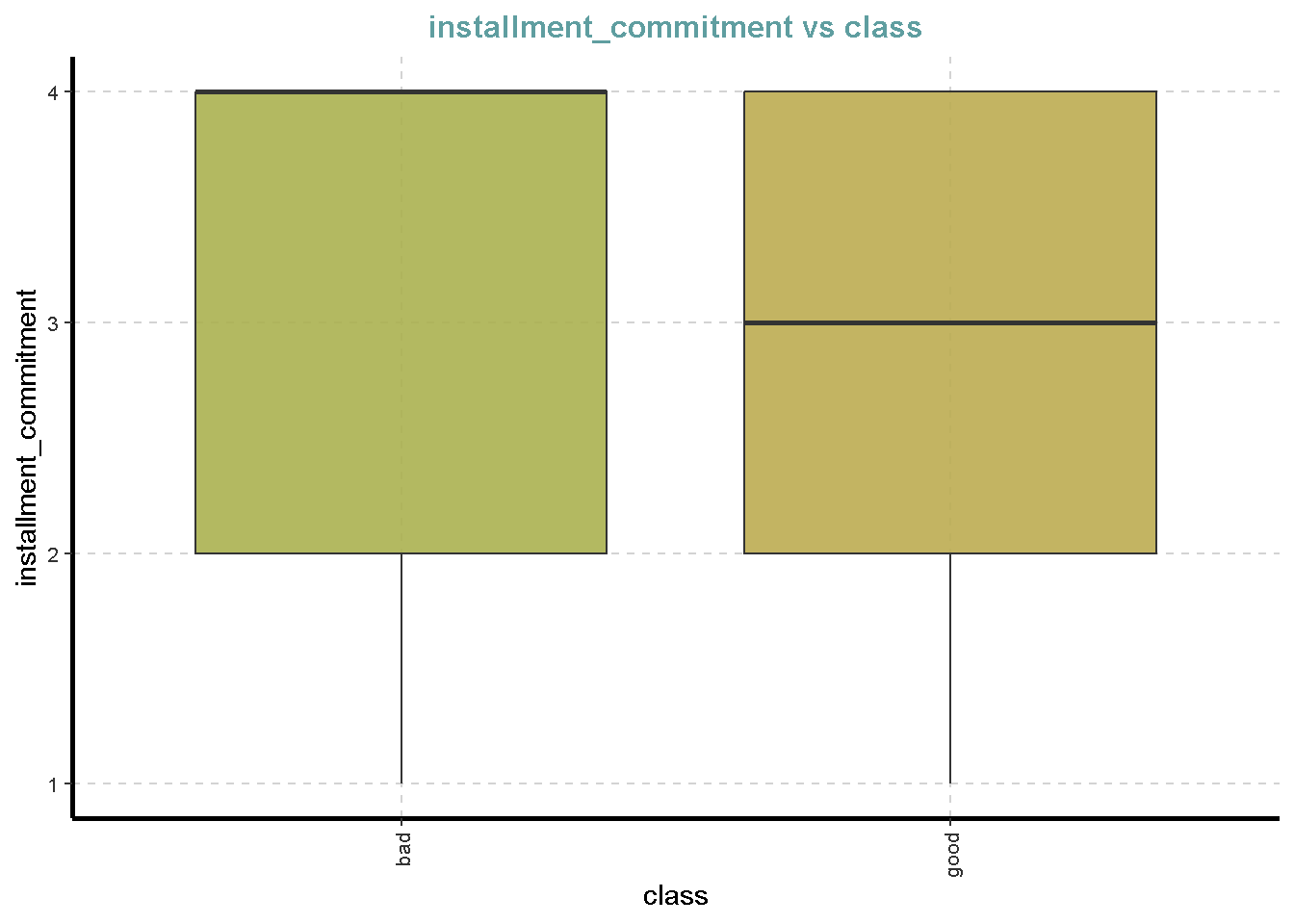
[[4]]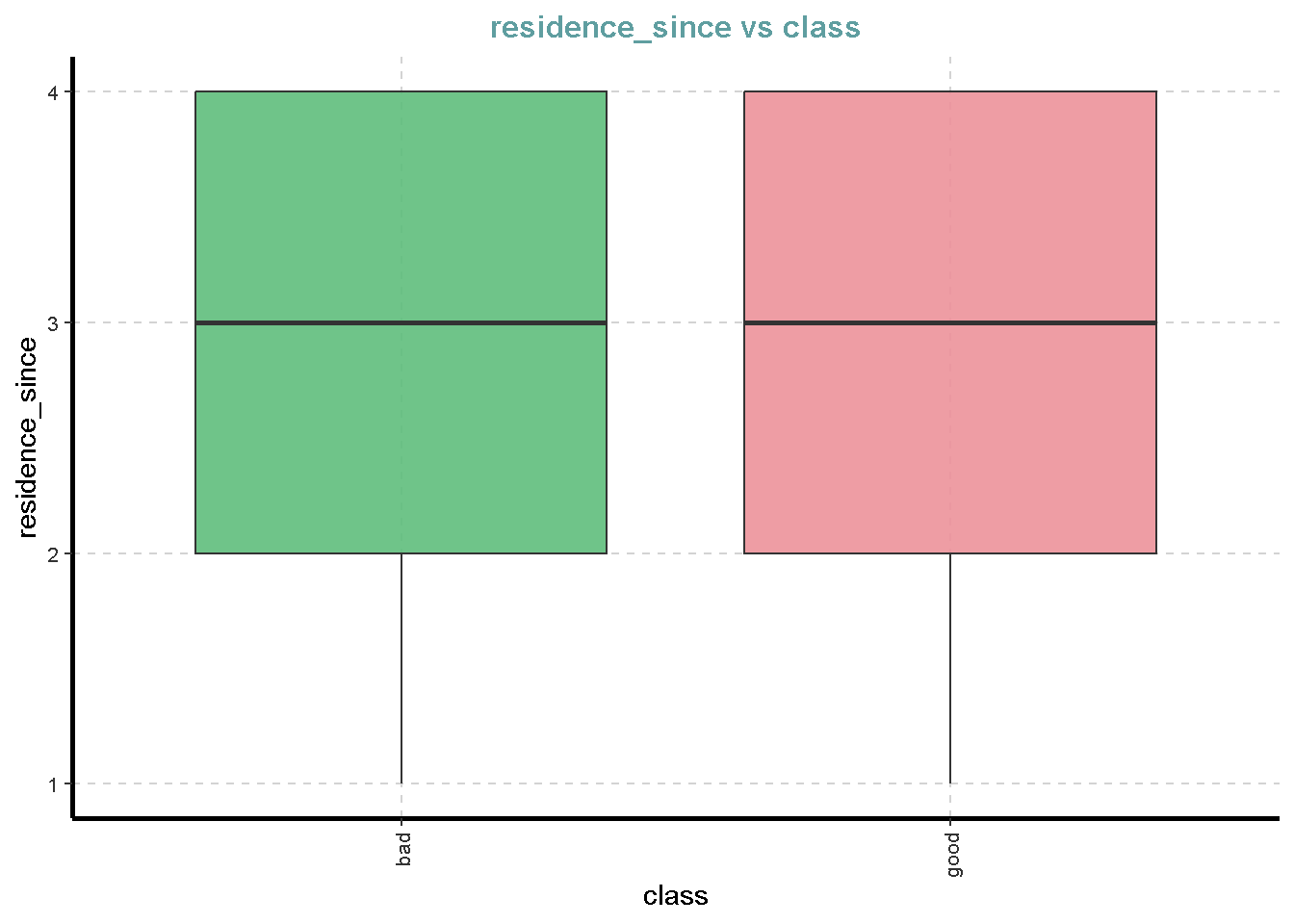
[[5]]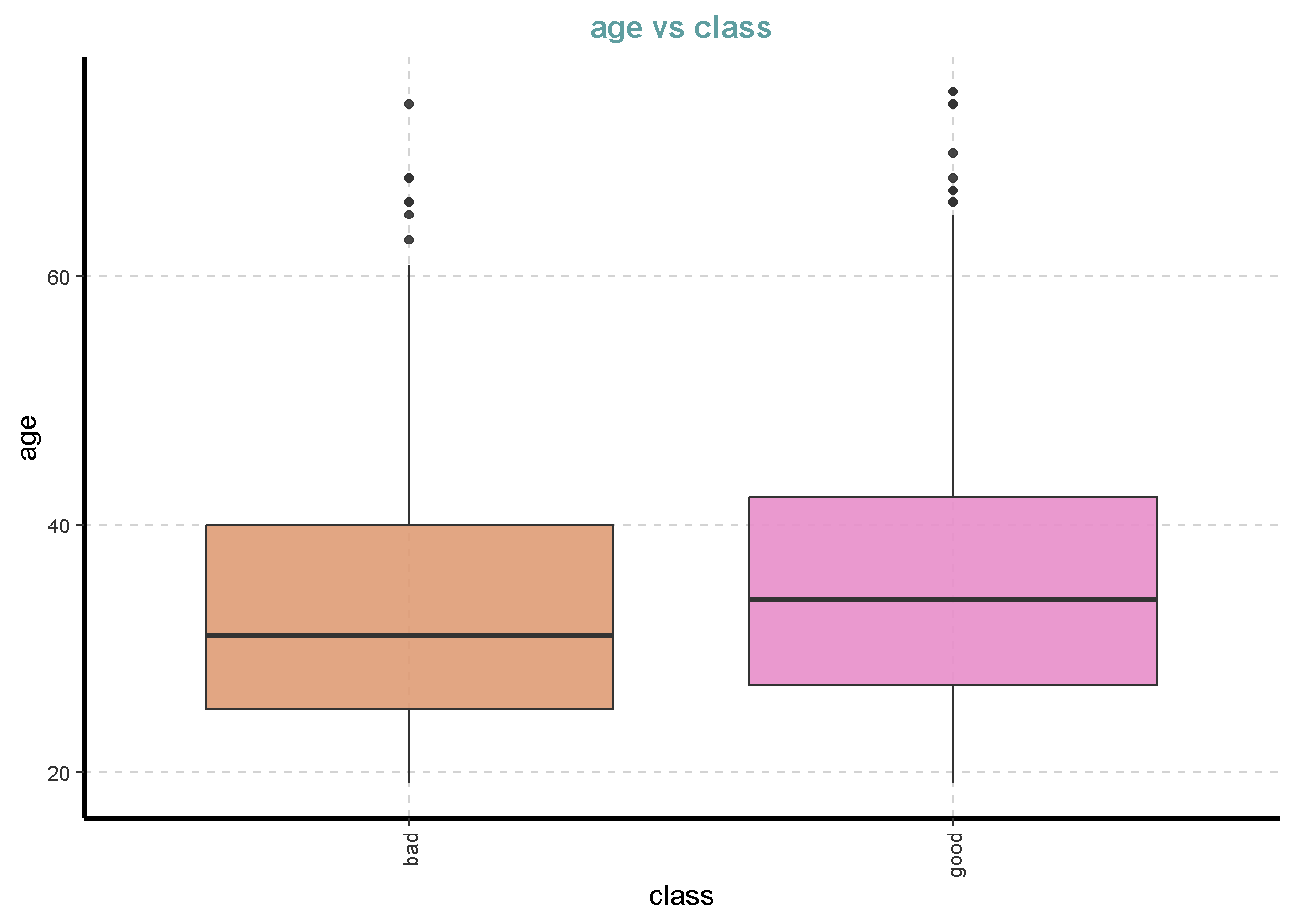
[[6]]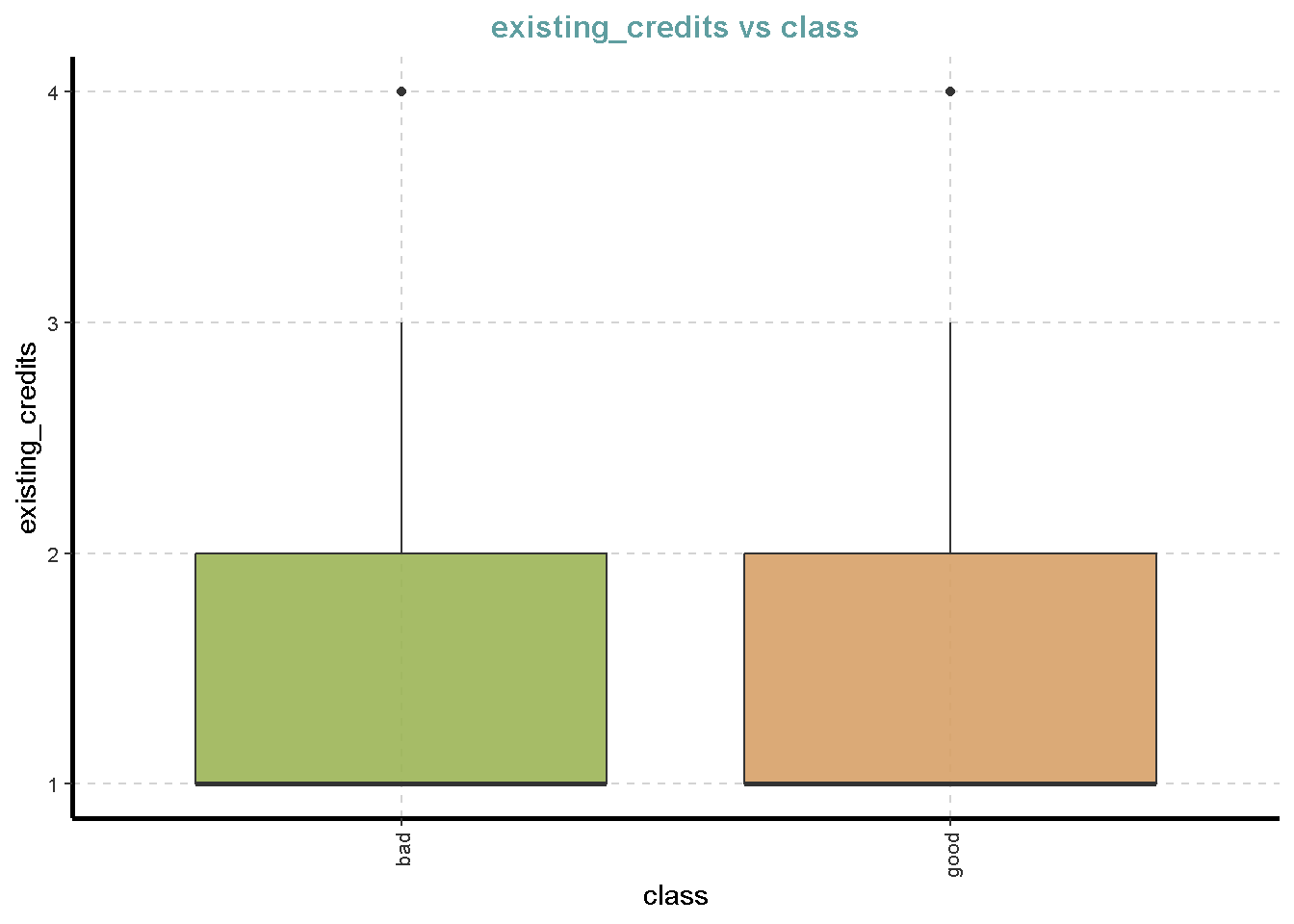
Deteksi Missing Value
df %>%
plot_missing(missing_only = FALSE,
ggtheme = theme_lares())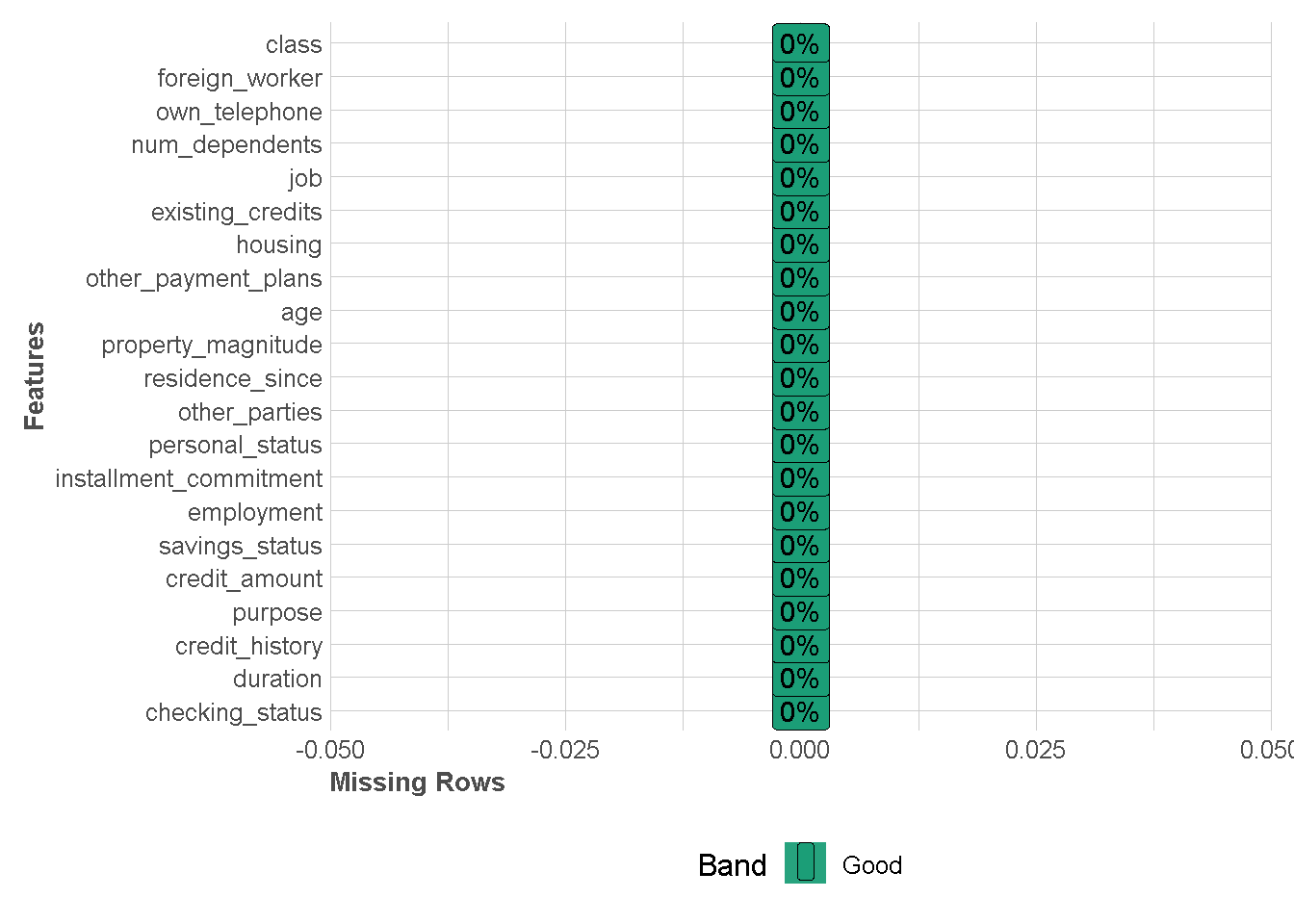
Pemodelan KNN
Menyiapkan Pembagian Data
Pembagian data bertujuan untuk mengevaluasi performa prediksi model klasifikasi. Evaluasi ini bisa dilakukan dengan melihat metrik-metrik tertentu seperti metrik akurasi, f1-score, dan lain-lain. Metode pembagian data yang sering digunakan ada dua yaitu Metode Holdout Sample dan K-fold Cross-Validation.
Holdout Sample
Metode ini membagi amatan pada dateset yang kita miliki menjadi dua bagian yaitu training data dan testing data. Secara umum, training data harus memiliki amatan yang lebih banyak dibandingkan testing data. Pembagian Banyaknya amatan ini bisanya direpresentasikan dalam bentuk proprosi atau persentasi seperti 0.8 atau 80%. Proses pembagian ini biasanya didasarkan pada pengambilan sampel acak.
set.seed(123)
holdout_split <- initial_split(df,
#sampel acak berdasarkan kelompok
strata = class,
# proporsi untuk training data
prop = 0.8)
train_data <- training(holdout_split)
test_data <- testing(holdout_split)tidy(holdout_split) %>%
count(Data) %>%
mutate(percent=n*100/sum(n))# custom function
split_class_info <- function(df,response){
df %>%
mutate(Row=seq(nrow(df))) %>%
select(all_of(response),Row) %>%
left_join(y = tidy(holdout_split),by = "Row") %>%
count(.data[[response]],Data) %>%
group_by(.data[[response]]) %>%
pivot_wider(id_cols = all_of(response),
names_from = Data,values_from = n)
}df %>%
split_class_info(response = "class")K-fold Cross Validation
K-fold Cross Validation adalah prosedur pengambilan sampel berulang yang melibatkan pembagian dataset menjadi K bagian yang sama besar atau hampir sama besar, yang disebut fold (lipatan). Ide dari metode ini adalah untuk training dan testing model klasifikasi sebanyak K kali, menggunakan fold(lipatan) yang berbeda sebagai testing data dalam setiap ulangan sambil menggunakan lipatan K-1 yang lain sebagai training data.
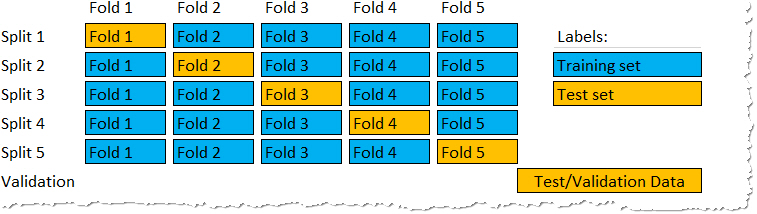

Pemilihan nilai K tergantung pada ukuran dataset dan trade-off antara waktu komputasi dan bias validasi. Nilai umum untuk K adalah 5 dan 10, tetapi kita dapat bereksperimen dengan nilai yang berbeda untuk menemukan keseimbangan terbaik untuk masalah spesifik.
set.seed(345)
folds <- vfold_cv(df, v = 10,strata = "class" )Contoh visualisasi 100 amatan pertama di setiap folds
tidy(folds) %>%
filter(Row<101) %>%
ggplot(aes(x = Fold, y = Row,fill = Data)) +
geom_tile()+
theme_lares()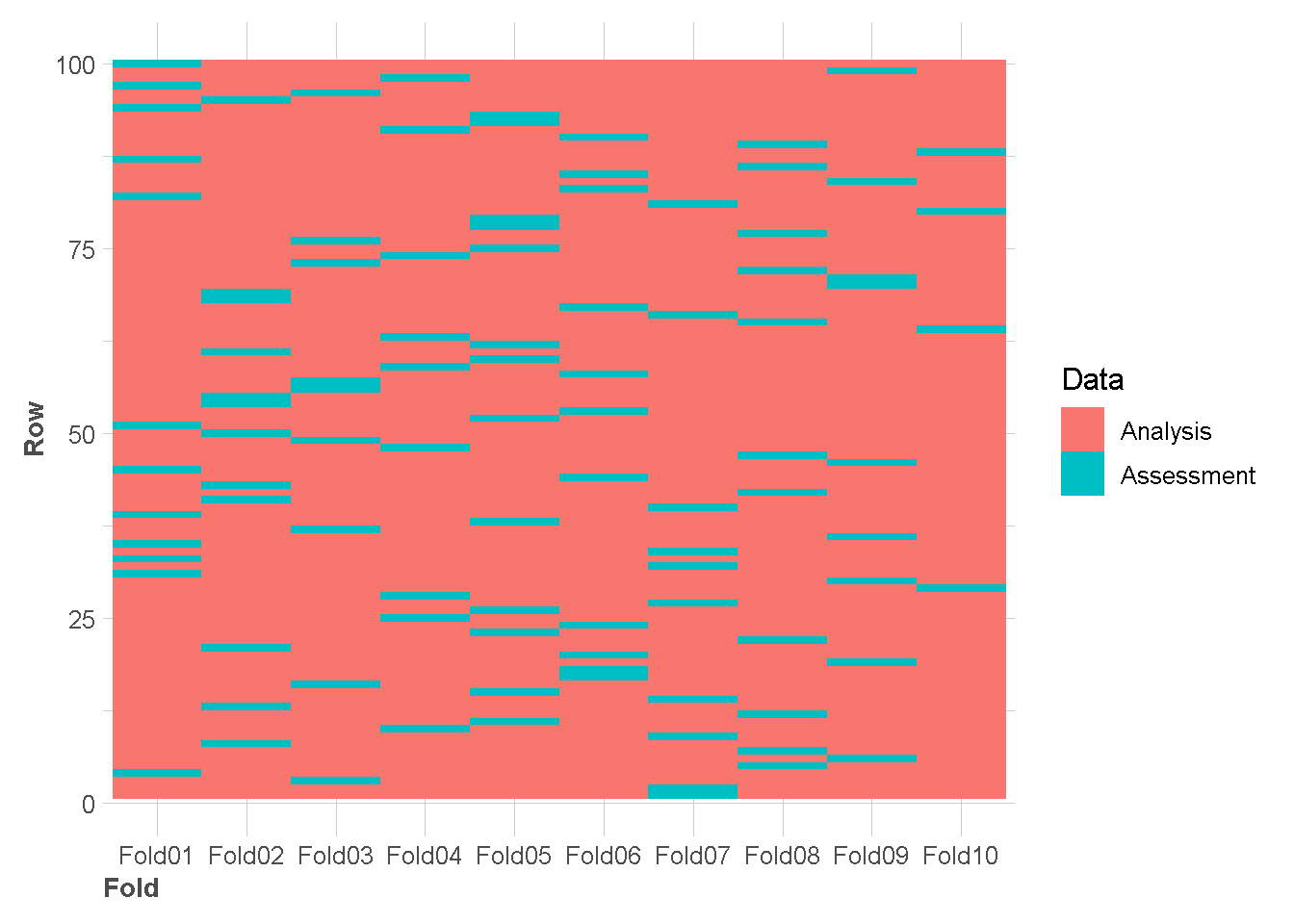
Mendefinisikan Model KNN
knn <- nearest_neighbor(neighbors=7,weight_func="rectangular") %>%
set_engine("kknn") %>%
set_mode("classification")knnK-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = 7
weight_func = rectangular
Computational engine: kknn knn %>% translate()K-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = 7
weight_func = rectangular
Computational engine: kknn
Model fit template:
kknn::train.kknn(formula = missing_arg(), data = missing_arg(),
ks = min_rows(7, data, 5), kernel = "rectangular")Evaluasi Model
Holdout Sample
Berikut adalah sintaks untuk training model KNN menggunakan training data
knn_hold <- knn %>%
fit(class~.,data=train_data)Selain sintaks diatas model klasifikasi bisa menggunakan fungsi workflow seperti dibawah ini
knn_hold2 <- workflow() %>%
add_formula(formula = class~.) %>%
add_model(knn) %>%
fit(data=train_data)extract_fit_engine(knn_hold)
Call:
kknn::train.kknn(formula = class ~ ., data = data, ks = min_rows(7, data, 5), kernel = ~"rectangular")
Type of response variable: nominal
Minimal misclassification: 0.2475
Best kernel: rectangular
Best k: 7extract_fit_engine(knn_hold2)
Call:
kknn::train.kknn(formula = ..y ~ ., data = data, ks = min_rows(7, data, 5), kernel = ~"rectangular")
Type of response variable: nominal
Minimal misclassification: 0.2775
Best kernel: rectangular
Best k: 7Sangat disarankan untuk proses training data menggunakan fungsi workflow seperti diatas.
Berikut adalah sintaks untuk mendapatkan prediksi KNN menggunakan testing data
pred_knn <- knn_hold2 %>%
predict(new_data = test_data) %>%
bind_cols(test_data %>% select(class))
pred_knn %>%
slice_head(n=10)Kemudian hasil prediksi tersebut akan kita evaluasi dengan menggunakan Confussion Matrix
confussion_matrix <- pred_knn %>%
conf_mat(truth=class,estimate=.pred_class)
autoplot(confussion_matrix,
type = "heatmap")+
scale_fill_viridis_c(direction = -1,
option = "inferno",
alpha = 0.6)Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.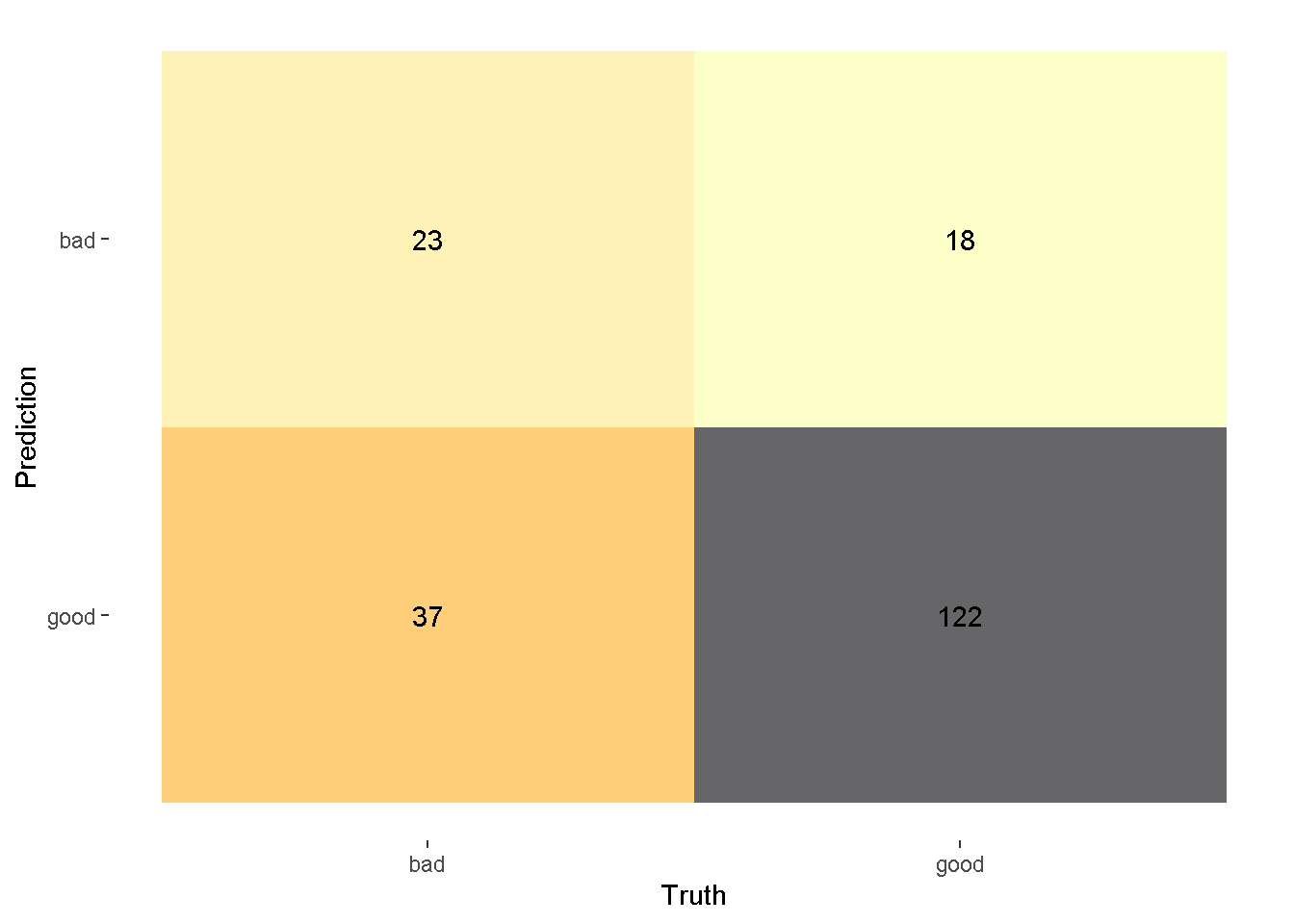
Dari Confussion Matrix tersebut kita bisa mendapatkan beberapa metrik dengan fungsi summary
pred_knn %>%
conf_mat(truth=class,estimate=.pred_class) %>%
summary()Kemudian kita evaluasi dapat juga langsung mendapatkan metrik akurasi dengan menggunakan accuracy.
pred_knn %>%
accuracy(truth=class,estimate=.pred_class)berikut adalah contoh penggunaan metric lainnya
## sensitivity
pred_knn %>%
sensitivity(truth=class,estimate=.pred_class)## specificity
pred_knn %>%
specificity(truth=class,estimate=.pred_class)## Balanced accuracy
pred_knn %>%
bal_accuracy(truth=class,estimate=.pred_class)## F1 score
pred_knn %>%
f_meas(truth=class,estimate=.pred_class,beta = 1)K-fold Cross Validation
knn_cv <-
workflow() %>%
add_formula(class~.) %>%
add_model(knn) %>%
fit_resamples(folds,
metrics=metric_set(accuracy,bal_accuracy),
control=control_resamples(save_pred = TRUE))confussion_matrix_cv <-
conf_mat_resampled(x = knn_cv,tidy = FALSE)autoplot(confussion_matrix_cv,type = "heatmap")+
scale_fill_viridis_c(direction = -1,
option = "inferno",
alpha = 0.6)Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.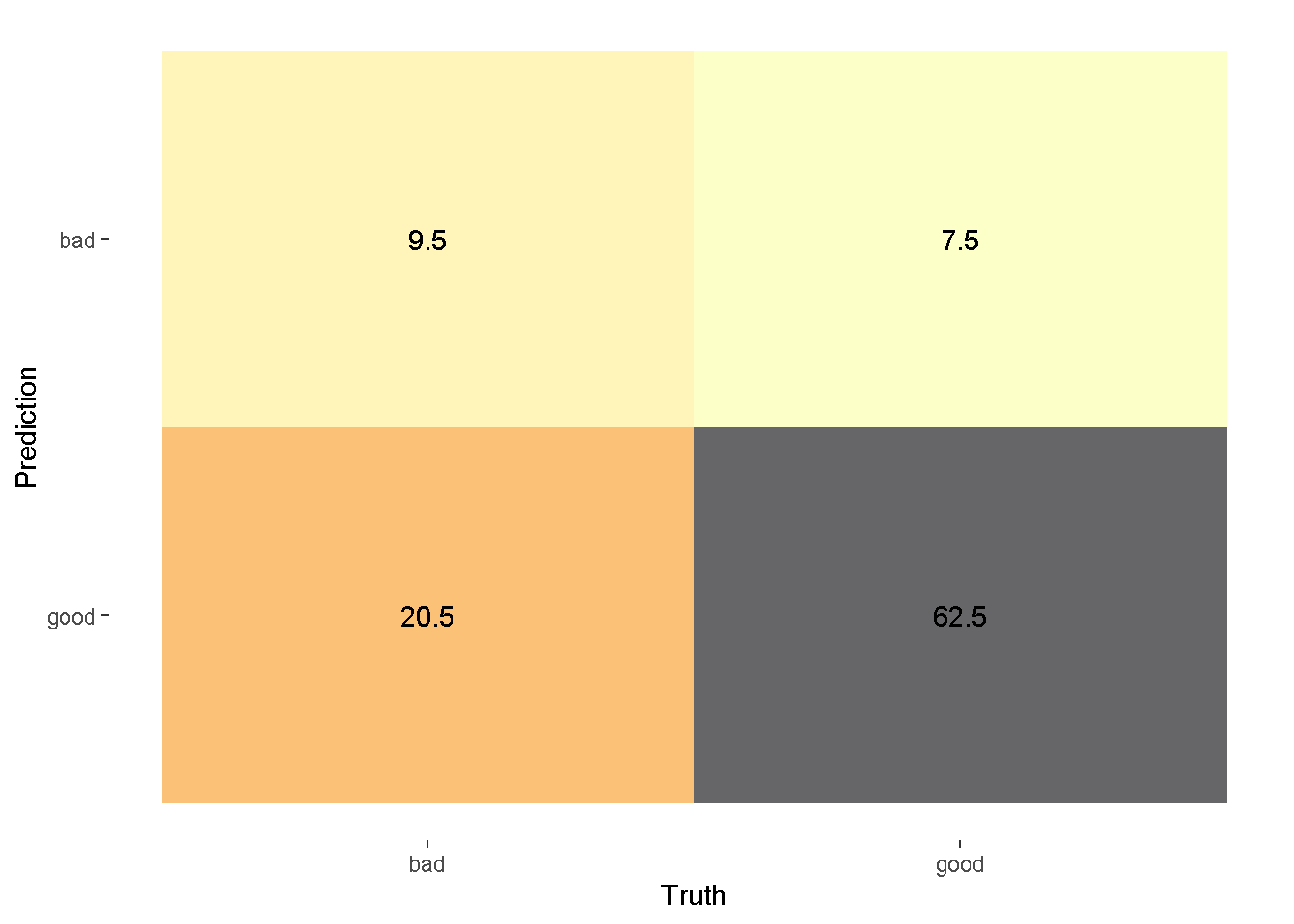
Gunakan secara hati-hati. Output confusion matriks diatas berupa desimal karena dihitung dari rata-rata setiap fold.
Berikut adalah cara menampilkan perhitungan metrik setiap fold
collect_metrics(knn_cv,summarize = FALSE)Berikut adalah cara menampilkan perhitungan metrik secara agregat dari fold.
collect_metrics(knn_cv,summarize = TRUE)Hyperparameter Tuning and Bias-Variance Trade-off
Hyperparameter Tuning dan Bias-Variance Trade-off sangat berkaitan erat
Hyperparameter Tuning Mempengaruhi Bias dan Variance:
- Saat melakukan Hyperparameter Tuning, pada dasarnya kita menyesuaikan pengaturan model untuk menemukan konfigurasi yang optimal.
- Pilihan hyperparameter untuk tuning dapat memiliki dampak langsung pada Bias dan Variance model.
- Meningkatkan kompleksitas model dengan Hyperparameter Tuning dapat mengurangi bias tetapi meningkatkan variance.
Hyperparameter Tuning sebagai Trade-off:
- Proses Hyperparameter Tuning pada dasarnya merupakan pencarian keseimbangan yang tepat antara bias dan variance model.
- Hyperparameter Tuning juga tentang mengidentifikasi titik optimal di mana model dapat menggeneralisasi dengan baik ke data baru namun juga menangkap pola penting dalam training data.
- Trade-off ini bertujuan untuk menghindari baik model yang underfitting maupun overfitting.
Cross Validation dan Tuning Hyperparameter:
- Dengan menggunakan Cross Validation, kita dapat membuat keputusan yang berdasarkan informasi tentang nilai hyperparameter mana yang dapat mencapai keseimbangan terbaik antara bias dan varian.
Hyperparameter Tuning untuk KNN
Hyperparameter pada KNN yang biasanya dilakukan Tuning adalah Hyperparameter banyaknya tetangga atau sering disimbolkan \(k\). Hyperparameter \(k\) dalam KNN merepresentasikan complexity of model (model kompleksitas). Semakin besar nilai \(k\) semakin tidak kompleks model KNN.
Pertama-tama kita definisikan dulu model KNN dan juga Hyperparameter yang akan kita tuning dengan fungsi tune.
knn_tune <- nearest_neighbor(neighbors=tune(),
weight_func="rectangular") %>%
set_engine("kknn") %>%
set_mode("classification")knn_tuneK-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = tune()
weight_func = rectangular
Computational engine: kknn Kemudian setelah itu, kita perlu menentukan nilai-nilai Hyperparameter yang akan kita gunakan.
knn_grid <- grid_regular(neighbors(range = c(2,50)),
levels= 50)
knn_grid #custom function
fitted_knn <- function(x){
mod <- extract_fit_engine(x)
fitted(mod)
}Kemudian kita mulai proses tuning dengan menggunakan bantuan tune_grid
knn_tune_cv <- workflow() %>%
add_formula(class~.) %>%
add_model(knn_tune) %>%
tune_grid(
resamples = folds,
grid = knn_grid,
metrics=metric_set(accuracy,bal_accuracy),
)## metric used information
metric_used <- knn_tune_cv %>%
collect_metrics() %>%
pull(.metric) %>%
unique()
metric_used[1] "accuracy" "bal_accuracy"## custom function
plot_neighbor<- function(tune_cv,metric){
tune_cv %>%
collect_metrics() %>%
filter(.metric%in%metric) %>%
ggplot(aes(x=neighbors, y=mean)) +
geom_errorbar(aes(ymin=(mean-std_err),
ymax=(mean+std_err)))+
geom_point()+
geom_vline(aes(xintercept = select_best(tune_cv,metric=metric)$neighbors,color="Highest"),
linetype="dashed",linewidth=0.8)+
geom_vline(aes(xintercept = select_by_one_std_err(tune_cv,metric=metric,desc(neighbors))$neighbors,
color="1-SE-Rule"
),
linetype="dashed",linewidth=0.8)+
ylab(metric) +
scale_x_continuous(n.breaks = 12)+
scale_color_manual(values = c("#03A9F4","#f44e03"),
breaks = c("Highest","1-SE-Rule"),
name = "Selection"
)+
theme_lares()+
theme(legend.position = "top")
}knn_tune_cv %>%
plot_neighbor(metric = metric_used[1])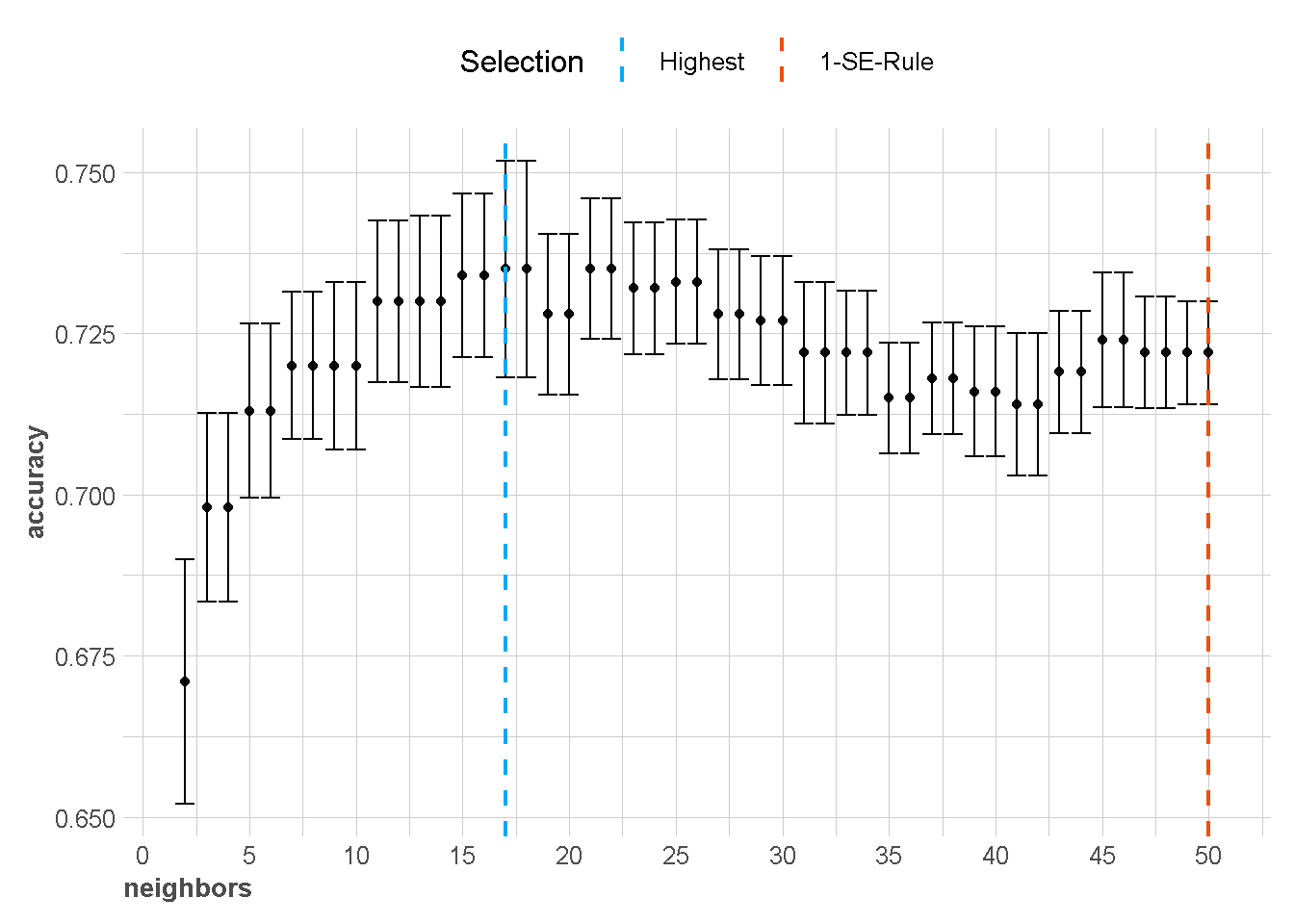
knn_tune_cv %>%
plot_neighbor(metric = metric_used[2])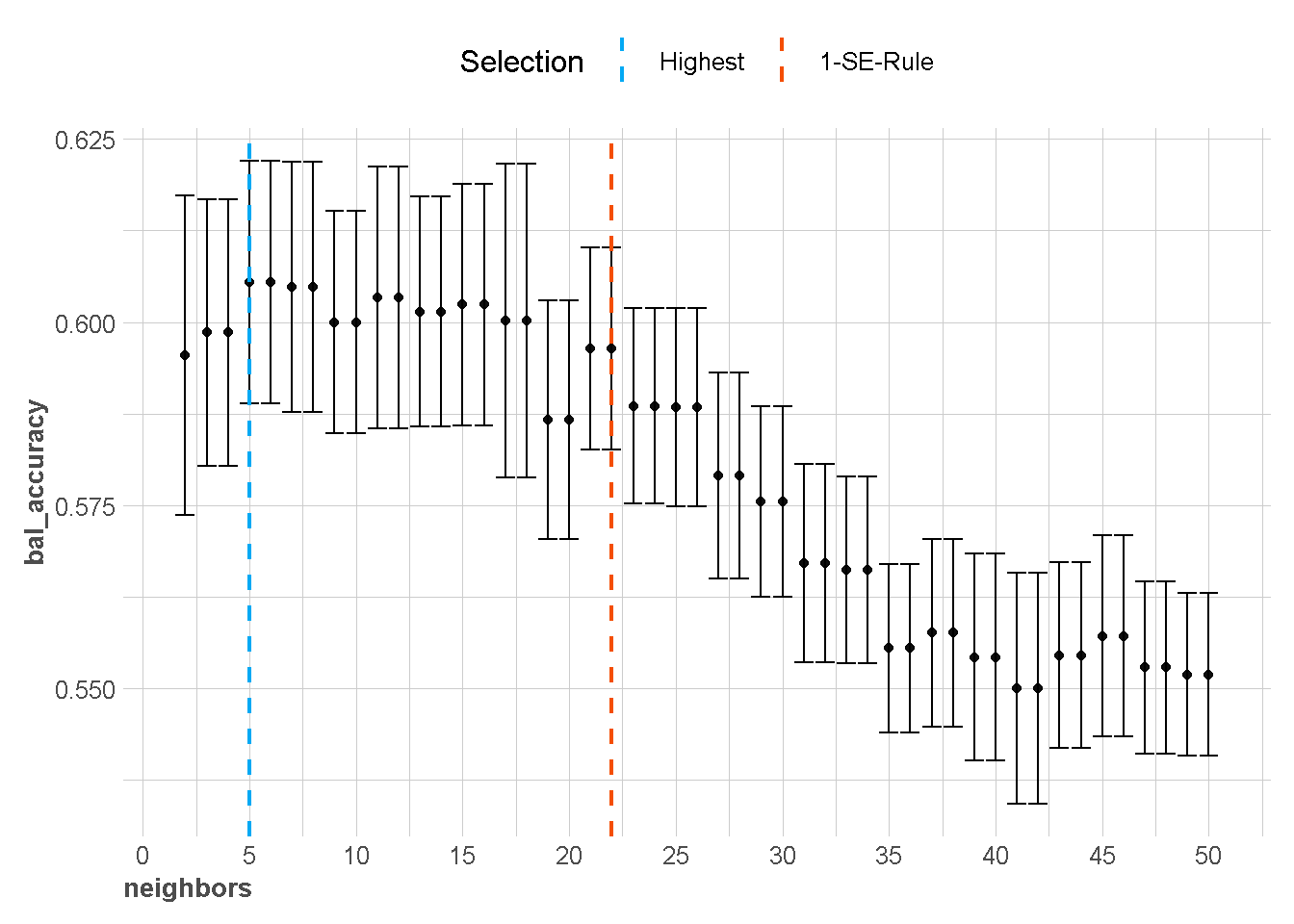
Berdasarkan grafik diatas, Hyperparameter \(k\) terbaik bisa dipilih menggunakan dua pendekatan yaitu menggunakan nilai metrik terbaik (akurasi tertinggi) atau menggunakan one standard error rule (1-SE-Rule).
collect_metrics(x = knn_tune_cv,summarize = FALSE)collect_metrics(x = knn_tune_cv,summarize = TRUE)Memilih model terbaik berdasarkan nilai accuarcy tertinggi
best1 <- select_best(x = knn_tune_cv,metric = metric_used[1])
best1Memilih model terbaik berdasarkan nilai balanced accuarcy tertinggi
best2 <- select_best(x = knn_tune_cv,metric = metric_used[2])
best2Memilih model terbaik berdasarkan aturan one standard error rule nilai accuarcy
best3 <- select_by_one_std_err(x = knn_tune_cv,desc(neighbors),
metric=metric_used[1])
best3Memilih model terbaik berdasarkan aturan one standard error rule nilai balanced accuarcy
best4 <- select_by_one_std_err(x = knn_tune_cv,desc(neighbors),
metric=metric_used[2])
best4Setelah kita mendapatkan hyperparameter terbaik, kita bisa menerapkannya langsung ke model dengan bantuan fungsi finalize_model
knn_opt2 <- knn_tune %>%
finalize_model(parameters = best2)
knn_opt3 <- knn_tune %>%
finalize_model(parameters = best3)knn_opt2K-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = 5
weight_func = rectangular
Computational engine: kknn knn_opt3K-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = 50
weight_func = rectangular
Computational engine: kknn Training Model KNN terbaik
Pada tahap ini kita akan melakukan training model dengan semua dataset yang kita miliki. Tentu saja hal ini dapat dilakukan dengan menggunakan fungsi workflow
knn_opt_fit2 <- workflow() %>%
add_formula(formula = class~.) %>%
add_model(knn_opt2) %>%
fit(data=df)
knn_opt_fit3 <- workflow() %>%
add_formula(formula = class~.) %>%
add_model(knn_opt3) %>%
fit(data=df)Prediksi Data baru
Berikut kita generate data baru dummy
set.seed(1234)
data_baru <- df %>%
slice_sample(n = 2,by = class) %>%
select(-class)
data_barupred_data_baru2 <- knn_opt_fit2 %>%
predict(new_data = data_baru)
pred_data_baru3 <- knn_opt_fit3 %>%
predict(new_data = data_baru)pred_data_baru2pred_data_baru3